

Announcing the Industry-First Multimodal LLM-as-a-Judge
Today, we are launching the industry-first Multimodal LLM-as-a-Judge (MLLM-as-a-Judge). The MLLM-as-a-Judge evaluation capability enables developers to score and optimize multimodal AI systems for image input to text output use cases. MLLM-as-a-judge represents the next phase of Patronus AI’s vision to advance scalable oversight of AI.
We are also thrilled to share that Etsy, the leading technology marketplace for independent sellers, uses Patronus AI’s MLLM-as-a-Judge to detect and mitigate caption hallucination from their product images.
The first MLLM-as-a-Judge
With the release of GPT-4o, Claude Opus, and Google’s Gemini over the last year, creative teams, e-commerce platforms, and others have invested in image generation to drive new customer value. However, as they scale these AI experiences, the unpredictability of LLM outputs scales as well. Images are less likely to be relevant to product searches or may contain hallucinations, leading to lower traction with users.
That’s why we developed the first MLLM-as-a-Judge. This is an LLM judge that supports image input to text output use cases, and has a Google Gemini backbone.
Prior research suggests that Google Gemini can serve as a reliable MLLM judge over alternatives like OpenAI’s GPT-4V1. GPT-4V was shown to exhibit greater levels of egocentricity, and Gemini had a more equitable approach to judgment given that it had a uniform scoring distribution. In our development of this MLLM judge, we also found that the Gemini backbone performed better compared to other multimodal LLMs, based on evaluation datasets we constructed internally.
Evaluating multimodal AI apps is a deeply iterative process. The following diagram describes how AI engineers can use this image MLLM judge, which we call Judge-Image, to iteratively measure and improve the quality of their multimodal AI apps:

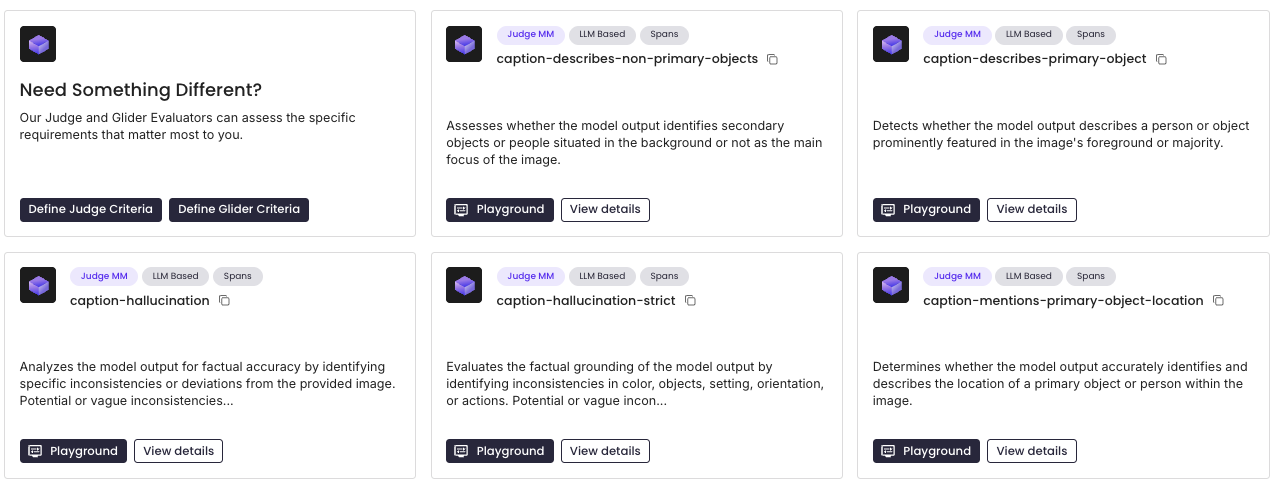
Step #3 here references the out-of-the-box evaluators supported for Judge-Image. These evaluators build a ground truth snapshot of the image by scanning for the presence of text and its location, grid structure, spatial orientation of objects and text, and object identification and description. Below is the full set of out-of-box criteria:
- caption-describes-non-primary-objects
- caption-describes-primary-object
- caption-hallucination
- caption-hallucination-strict
- caption-mentions-primary-object-location
Beyond validating image caption correctness, other sample use cases for Judge-Image include:
- Testing whether user queries are surfacing the most relevant product screenshots
- Testing whether OCR extraction for tabular data is accurate
- Testing whether AI-generated brand images, logos, and listings are accurate
- Testing whether captions accurately describe image scenes
In the future, we plan to support audio and vision capabilities as well! 🚀👀
How Etsy uses Patronus

Etsy is a global e-commerce platform for handmade and vintage products, and has over hundreds of millions of items in its online marketplace. One key use case the Etsy AI team is leveraging generative AI for is autogenerating captions on product images uploaded by Etsy sellers, to help speed up the seller listing process. However, they kept running into quality issues with their multimodal AI systems – the autogenerated captions frequently contained errors and other unexpected outputs.
In order to solve this challenge, the Etsy AI team used Judge-Image and the broader platform to scalably optimize their multimodal AI system. Below, you can see an example image being evaluated against the caption in a Patronus Log:

As shown above, Patronus captures and renders the input image along with a confidence score and reasoning for its decision. The Etsy team leverages the reasoning along with the Patronus Experiments frameworks to improve their image captioning and reduce hallucinations.
Here is an example on how to run a multimodal eval experiment in code:
from patronus import Client
client = Client(api_key="")
caption_hallucination = client.remote_evaluator("judge-image", "patronus:caption-hallucination")
caption_primary_object = client.remote_evaluator("judge-image", "patronus:caption-describes-primary-object")
caption_nonprimary_object = client.remote_evaluator("judge-image", "patronus:caption-describes-non-primary-objects")
client.evaluate(
evaluator = "judge-image",
criteria = "patronus:caption-hallucination",
evaluated_model_output = "Power surges with every stride. A relentless athlete carves their path, muscles burning, heart pounding, eyes locked on the finish. The sun dips low, sweat glistens, and the world fades—just the sound of breath, footfalls, and the quiet promise of greatness. No shortcuts. No limits. Just the drive to push further. Just do it.",
evaluated_model_attachments = [
{
"media_type": "image/jpeg",
"url": "https://i.guim.co.uk/img/media/05dffa08fc193b274f58ce189ccc58e50b0317b8/54_0_1148_689/master/1148.png?width=1200&height=900&quality=85&auto=format&fit=crop&s=65338298e89b98ea065e5759c8a62229"
}
],
explain_strategy = "always",
capture = "all",
tags = {"dataset_key": "8233883", "model_key": "claude-opus", "system_prompt": "This is an image for which you need to generate a caption."}
)
The Patronus AI’s Experimentation framework enabled the Etsy team to iterate on the architecture of their LLM system, and compare performance on datasets of images with time.
The screenshot below shows the performance of two different multimodal models on the caption-hallucination evaluator:

Here is an example query to the Patronus API with image inputs:
from patronus.evals import RemoteEvaluator
caption_hallucination = RemoteEvaluator("judge-image", "patronus:caption-hallucination")
caption_describes_primary_object = RemoteEvaluator("judge-image", "patronus:caption-describes-primary-object")
caption_describes_non_primary_objects = RemoteEvaluator("judge-image", "patronus:caption-describes-non-primary-objects")
caption_mentions_primary_object_location = RemoteEvaluator("judge-image","patronus:caption-mentions-primary-object-location")
caption_hallucination_strict = RemoteEvaluator("judge-image", "patronus:caption-hallucination-strict")
caption_hallucination.evaluate(
task_output="""A skilled gymnast soars in a flawless arch above the beam, her body elegantly extended in a full rotation. Her concentrated gaze and tensed muscles reflect years of discipline and training, as she transitions from takeoff to a poised landing. With arms gracefully outstretched, she demonstrates both precision and artistry, highlighting the athletic mastery required to execute such a breathtaking maneuver. The narrow beam beneath her contrasts sharply with her fluid, controlled motion, underscoring the delicate balance and unwavering focus it takes to perform at this elite level.""",
task_attachments=[
{
"media_type": "image/jpeg",
"url": "https://d2z00kf51ll94q.cloudfront.net/archive/2019/large/OS_FI19007S_12.jpg",
}
]
)
And that’s all for now!
Read more in the docs, or reach out to us at contact@patronus.ai to learn more. 🚀

