

AI Reliability: Tutorial & Best Practices
You’re probably already well aware that AI doesn’t always perform as expected or desired. AI systems sometimes produce incorrect or inconsistent outputs, making them unreliable for use in high-stakes contexts. In other cases, AI systems may be unreliable due to inconsistent availability, frequent crashes, or high latency that doesn’t permit the user to get responses as quickly as needed.
We can divide the space of AI reliability into three subcategories: correctness, consistency, and availability, as shown in the figure below.
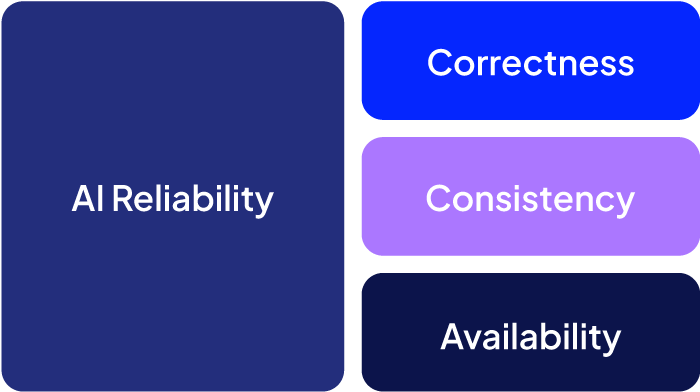
For AI to be useful, it must be correct. Large language models (LLMs) often hallucinate, confidently generating false information that, when relied upon, can have serious real-world consequences. Notable examples include New York lawyers being sanctioned for submitting AI-generated briefs with fabricated case law and a man who developed bromide poisoning after ChatGPT incorrectly suggested replacing table salt with sodium bromide.
Equally important is consistency: LLMs are nondeterministic and highly sensitive to minor prompt variations, producing different answers to semantically equivalent questions. Even the most minor changes, like adding greetings or just a single additional space, can cause variations in LLM responses.
Finally, latency poses challenges for LLMs. Complex prompts can take minutes to process, which is sometimes acceptable but can be problematic for systems handling millions of queries each day. Time-sensitive functions also require high system reliability and uptime.
Unreliable AI is sometimes amusing (remember “how many ‘R’s in strawberry?”) but can also have serious real-world consequences for those who overly rely on it. AI reliability must be considered throughout all stages of the design, development, and deployment of your system.
In this article, we describe the three components of AI reliability in the context of LLMs and retrieval-augmented generation (RAG) and discuss how to assess and improve the reliability of your LLM- and RAG-based AI systems.
Summary of key AI reliability concepts
{{banner-large-dark-2="/banners"}}
Correctness
AI correctness is the first key component of AI reliability; it describes the degree to which the AI system behaves as expected, generating accurate outputs. The tendency of LLMs to hallucinate wastes users’ time, erodes user trust, and creates barriers to adoption.
This erosion in trust can have significant business impacts. For instance, Alphabet, Inc. lost $100 billion in market value after its AI chatbot, Bard, provided incorrect information about which telescope was the first to be used to take pictures of a planet outside the Earth's solar system during its first public demo.
Incorrectly relying on hallucinated content or serving it up to customers can also have direct business costs. The New York lawyers mentioned above who used hallucinated case law in a legal brief were fined $5,000 and rebuked for acting in bad faith. Air Canada was required to compensate a customer who had relied on its chatbot’s hallucinated retroactive bereavement fare policy.
Over-reliance on incorrect medical, legal, or financial advice from LLMs has serious human consequences. Medical harms can include delayed, missed, or incorrect diagnosis, dangerous drug interactions, and inappropriate treatment recommendations. Relying on incorrect or incomplete legal advice can have a myriad of negative criminal and civil consequences. Likewise, inaccurate investment or tax advice can have a substantial financial cost.
In such high-stakes fields, many jurisdictions have begun implementing regulations that address the correctness of AI outputs, but those regulations are still fragmented and rapidly evolving. Emerging best practice calls for strong evidence grounding to permit human oversight.
Even in highly reliable systems, small errors can accumulate, propagating through pipelines and becoming amplified when an erroneous output becomes the input to the next process. When multiple steps of a process involve a small level of uncertainty, the combined uncertainty in the entire process grows non-linearly with the number of steps. Humans are biased toward trusting systems like LLMs that sound coherent and confident, which can allow minor errors to elude detection. This can lead to a miscalibration of trust in the AI system where the user trusts the system more than they should because they overestimate the system's level of accuracy.
Tool-calling agentic AI systems can also suffer from a number of unique challenges, including incorrect tool selection, hallucinated tool capabilities, improper tool input formatting, misinterpreting tool outputs, and incorrect context handling. This makes careful design and monitoring of agentic system correctness even more important.
Building for correctness
This section provides a brief overview of some of the most common approaches to building LLM systems, with a focus on the correctness of the outputs.
Prompt engineering for correctness
A first step in ensuring the correctness of LLM output involves prompt engineering to ensure that instructions to the LLM clearly describe the desired output and correct output format. Customizing the system prompt can give the LLM a role definition, guidelines for the model to follow, and additional context to aid task completion (sometimes called context stuffing). Chain-of-thought prompting can improve the accuracy of LLMs on tasks that require reasoning by structuring the input prompt in a way that encourages the AI to attack the problem step by step.
Retrieval-augmented generation
When it is important for the AI to answer questions based on a given corpus of documents—such as a chatbot answering questions about the content of a specific set of regulations—retrieval-augmented generation (RAG) attempts to constrain the LLM to using chunks retrieved from the document corpus as context for the response rather than using its parametric knowledge.
RAG uses a two-step process where an information-retrieval step is first used to retrieve relevant chunks of text from a provided knowledge base (corpus of documents) and then a generation step is used to generate a response to the query based on the content in the retrieved chunks. Ideally, the generation step uses the foundation model’s parametric knowledge for general language capabilities but restricts the domain-specific knowledge it draws on to what is given in the retrieved context chunks.
The image below provides an overview of the steps in setting up and using a RAG system. Step 1 is the initial set up of the vector store created by chunking and embedding the document corpus. Steps 2 and 3 are the retrieval and generation steps, respectively.

RAG systems are often set up to cite the documents they pulled their answers from, increasing user trust. This can work well when the answer is found within the documents, but even RAG systems have a tendency to hallucinate when they don’t have access to the correct answer within the retrieved context chunks. This can happen if the information is not present in the corpus but can also result from a failure of the retrieval step to retrieve the correct documents, a problem sometimes called RAG recall failure.
These systems run into correctness issues when the information needed to answer the question crosses a chunk boundary, preventing the generation step from accessing the full context. This risk can be reduced by implementing intelligent chunking strategies that respect document structure (keeping paragraphs, tables, and lists intact).
RAG systems also struggle when answering questions that require synthesizing information from multiple retrieved documents or chunks, a process called multi-hop reasoning. The retrieval step may fail to retrieve all the necessary context, or the generation step may fail to reason over the combined content appropriately. A limited context window can also make it impossible for the system to leverage all of the retrieved context. You may need to increase your context window and use multilevel retrieval or iterative deepening to avoid these challenges.
Model selection and tuning
Careful consideration should be given to selecting the right LLM for a specific use case, as each has its own strengths and weaknesses, and some are specialized for particular types of tasks, such as coding or reasoning. In the case of tasks where no off-the-shelf model excels out of the box, fine-tuning can be used to improve the model’s accuracy, provided that good-quality data is available or can be created.
Guardrails
Adding output validation and guardrails to check the LLM’s response before providing it to the user is another way of improving correctness. These approaches can be used to ensure that the correct output format is used, detect instances of RAG outputs not consistent with the retrieved context, confirm the validity of citations, etc. Guardrails can also be used to detect and eliminate harmful or toxic outputs before the user sees them.
Feedback mechanisms
Building in user feedback mechanisms can provide important task-appropriate feedback about where an AI system falls short and can catch edge cases that routine testing misses. Such feedback should be used for continuous improvement of your system either by automatically feeding in additional training examples as they occur (if you can trust your users not to use the feature adversarially) or by reviewing the logs manually and implementing improvements.
Final thoughts on building for correctness
LLM and RAG correctness is a rapidly evolving field, with new approaches to improving LLM correctness being proposed daily. Whatever approaches you choose, you will need to continually assess how well they work for your use case.
Correctness testing and monitoring
The most common way of assessing LLM and RAG correctness is through evaluation datasets and benchmark suites (either standardized or custom-built for your task). The choice of benchmarks and metrics will depend on the nature of your task and the domain of the content.
Metrics for classification tasks
For classification-type tasks such as named entity recognition or sentiment analysis, the traditional precision, recall, and F1 metrics are still ideal. For information retrieval tasks, including the retrieval element of a RAG system, metrics like precision@k (and, where there is a known, limited set of relevant documents, the analogous recall@k) are used, along with mean reciprocal rank (MRR) and normalized discounted cumulative gain (nDCG).
Assessing open-ended generation
For open-ended generation tasks, traditional metrics are harder to apply directly. There have been some attempts to use machine translation metrics like BLEU, ROUGE, or METEOR. However, these are not ideal for open-ended tasks because they require a reference answer and assess lexical similarity to that answer but would give a low score to a semantically equivalent response that used different vocabulary. BERTScore, based on contextual embeddings, can be used to assess semantic similarity to a reference answer.
The gold standard evaluation for these open-ended generation tasks is human evaluation (often crowdsourced), though this is costly and slow. Here, evaluators are asked to judge the response across several dimensions like fluency, coherence, informativeness, relevance, factuality, helpfulness, etc., typically using Likert scales. Ideally, assessment is based on multiple annotators per example, and annotators should be provided with clear rubrics containing examples and edge cases.
Inter-annotator agreement metrics help you understand the reliability and validity of the evaluation. Low agreement suggests that the task may be ambiguous or too nuanced, the rubrics may be insufficiently clear or complete, or the annotators may be insufficiently trained or fatigued.
An alternative to costly human evaluation is using an LLM-as-a-judge approach where an LLM judge is fine-tuned or employs prompt engineering techniques to mimic human judgment. The judge can either be used to score a single prompt-response pair or select a preference between two. Humans should still oversee this approach to ensure quality.
Correctness benchmarks
There is an ever-growing number of LLM benchmarks that can be used to assess correctness in a variety of domains, such as FinanceBench, MATH, or MBPP (Mostly Basic Python Programs). A benchmark consists of test problems with correct answers:
- FinanceBench is a question-answering (QA) benchmark testing an LLM’s ability to extract and reason over information found in financial documents like 10-K filings. Because it provides the document that contains the information to answer the question, it can be used to test the generation portion of a RAG system.
- MATH is a dataset of competition-level math problems requiring multi-step reasoning and symbolic manipulation; it is used to distinguish between reasoning models on challenging mathematical tasks.
- MBPP is a code generation benchmark used to assess programming ability, API knowledge, and the ability to translate natural language specifications into functionally correct code.
With RAG systems, be sure to test queries that explicitly require multi-hop reasoning. MultiHop-RAG is one such benchmark, but ideally, you would create your own that uses your own knowledge base and that tests the kind of multi-hop reasoning characteristic of your domain.
Benchmarking metrics
Question-answering benchmarks typically score the percentage of test items for which the LLM generated the correct answer, an approach that is suitable for benchmarks like FinanceBench where each item has a single correct answer. Other benchmarks may have multiple possible representations of the correct answer provided as acceptable answers, such as having “USA,” “United States,” and “United States of America” listed as possible answers to a given question. In long-form QA benchmarks like ELI5 (Explain Like I’m 5), a reference answer will be provided, and the scoring uses ROUGE and BERTScore.
In addition to scoring the percentage of correct answers, a reasoning benchmark offers the opportunity to score the reasoning chain’s validity, the percentage of steps that are correct, and the step at which the model makes its first error. This can be done using either manual or LLM-as-a-judge evaluation. It is also common to compute pass@k by generating k solutions and checking whether at least one is correct or assessing whether a majority vote among multiple solutions identifies the correct answer. Pass@k is also the standard metric used for code generation benchmarks.
Specialized classifiers and error detection models
Specialized classifiers can be used for things like automated entailment checking and toxicity or safety filters. These must be paired with sampling for validation by human evaluators, as these tools are imperfect.
A hallucination detector like Lynx can be used to flag RAG responses that are not faithful to the retrieved context.
Assessing format correctness
In addition to content correctness, it is often important to evaluate format correctness, especially in cases where your AI is not directly user-facing but rather part of a pipeline. This can usually be done programmatically, for example, by checking a JSON response against the schema or using a regex. Other automated correctness checks can include constraint validation, such as numeric bounds or required fields.
A/B testing
No matter what your criteria for correctness are, A/B testing can be used to compare different LLMs (or different system prompts or settings for the same LLM) to determine which is best for your needs.
Agentic AI testing
Agentic AI is prone to a large number of error types, and those errors can cascade through complex agentic systems, which means a tool like Percival that is designed to assist in testing and debugging agentic AI systems can be extremely helpful. Percival is an adaptive learning evaluation agent that ingests your agent traces and generates a summary of errors and optimizations.
Compliance testing
If your AI is operating in an industry regulated by legal compliance requirements, you will also need to do ongoing compliance testing. This can involve steps like auditing model outputs for compliance, documenting decision-making processes, and implementing data retention policies according to the specific regulatory guidelines. Please consult a source specific to your regulatory environment for the necessary details.
Consistency
AI consistency is the second key component of AI reliability.
LLMs have introduced a new wrinkle to the consistency conundrum by being much less deterministic than traditional AI approaches. This can be beneficial for creative tasks like brainstorming, solution space exploration, and creative endeavors. It also leads to more natural and human-sounding text replies, which can be either a benefit or a liability, depending on the context. In many business cases, you don’t want your users anthropomorphizing your AI and either over-trusting it or winding up in a linguistic uncanny valley.
However, consistency is important when you need reproducibility, whether in a scientific context, a regulatory/audit context, or to ensure equity by responding to equivalent inputs in the same way. For example, if you score the same resume differently on different days or differently for certain genders or ethnicities or names, candidates are being assessed unfairly, to both the candidates’ and the employer’s detriment. Consistency is also necessary to ensure reliable workflows and integrations.
Consistency and correctness go hand in hand: The greater the inconsistency, the less confident you can be in the system's capability of producing the correct answer, despite sometimes incidentally generating a good response. Thus, when users notice inconsistency in an AI system, their trust in the system typically becomes substantially degraded. If the system is inconsistent in quality, it is difficult for the user’s trust to be appropriately calibrated, leading to users trusting the system either too much or too little relative to the system’s actual ability (which they cannot reliably estimate).
In many cases, you will also want to add guardrails to ensure that your LLM-based system maintains brand voice and style expectations and adheres to policies and guidelines.
Drift
Various types of drift can create inconsistencies that challenge the reliable performance of the system, the most significant of which are described in the table below.
Building for consistency
While you always need your LLM outputs to be correct, the degree to which you need them to be consistent depends on your use case and objectives. When designing and building your system, it will be important for you to give careful consideration to your consistency needs and goals. This section describes the most common approaches to building consistent LLM-based systems.
Setting model parameters for consistency
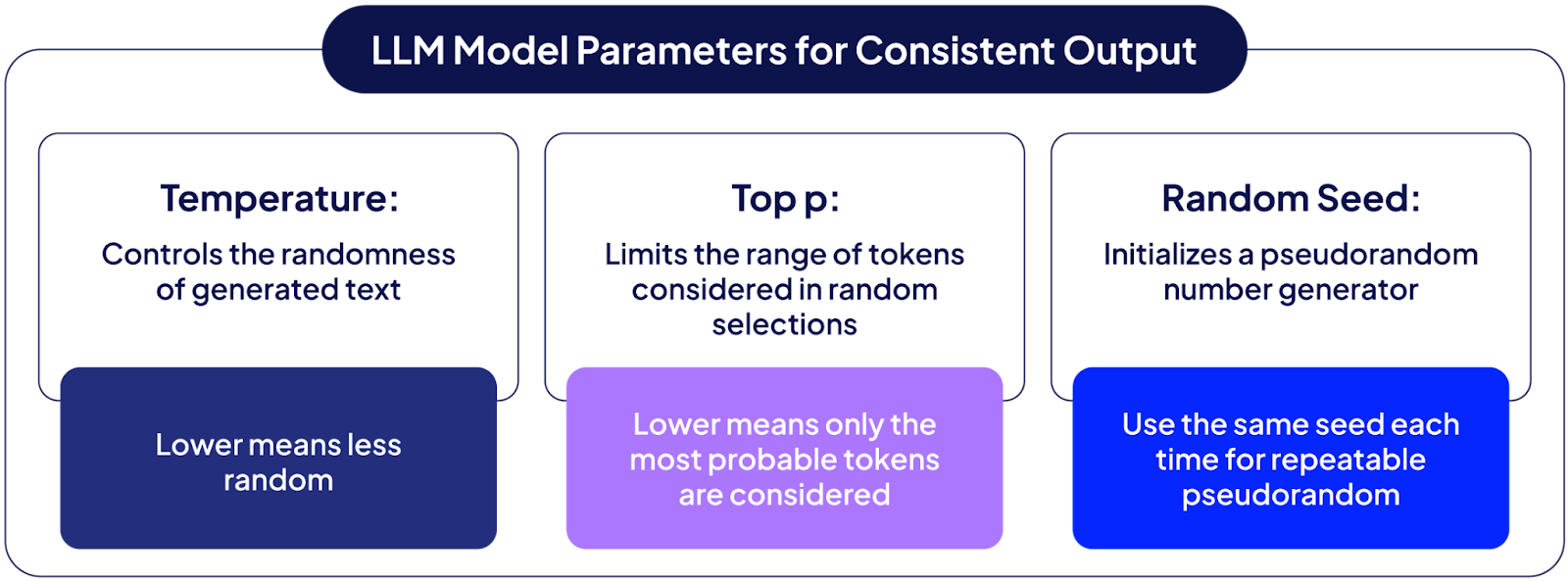
When working with LLMs, one of the easiest things you can do to increase consistency is to set the temperature to zero (or if you absolutely need some variance/creativity, start near zero and tune upwards). If you are using a non-zero temperature setting, you can use a low value for top_p sampling to limit randomness. If the API you are using has a seed parameter to initialize the random number generator, setting it to the same value each time will help ensure more predictable behavior. You can also set up your RAG systems to use deterministic retrieval ranking and context ordering settings.
Prompt engineering guardrails for consistency
Create system prompts that introduce explicit guidelines for brand voice, style, and policy compliance and that include sample outputs illustrating these boundaries via both in-bounds and out-of-bounds examples. Supplement this with content filters to detect and reject out-of-bounds responses, maximizing the consistency of voice and style and ensuring consistent compliance with policy.
Avoiding drift
In general, drift must be detected by ongoing monitoring, but there are some steps you can take at build time. For instance, the impacts of usage drift can be mitigated by recognizing out-of-distribution inputs and creating fallback behaviors.
To avoid corpus drift in RAG systems, organize your knowledge base (KB) well, so you can easily find and remove outdated documents and replace updated ones. Where possible, consolidate overlapping documents, keeping a single, authoritative version per topic, and schedule regular reviews to keep content fresh and relevant. Document the purpose and content of the KB to facilitate the detection of out-of-scope queries.
To avoid embedding drift in your RAG system, carefully track the version of the embedding model used to index the KB and be sure to use that same model for all new documents and queries. When the embedding model changes, you must reindex the entire corpus—old and new embeddings cannot be used together.
Consistency testing and monitoring
This section describes some of the ways you can evaluate and monitor the consistency of your LLM-based system.
Measuring diversity
Diversity metrics, such as Self-BLEU (lexical diversity) or BERTScore diversity (using BERTScore analogously to the BLEU score in Self-BLEU to get at semantic diversity) can measure the variety of generated text for the same or equivalent inputs. The diversity Python package and the paper that introduced it offer a number of other computationally efficient diversity measures.
These metrics can be used against sets of outputs produced using:
- Identical inputs and identical system settings
- Identical inputs with different system settings (e.g., changing the random seed)
- Inputs with minor changes (e.g., capitalization, spacing, or typos)
- Equivalent inputs (e.g., wording the question differently or expressing numerical inputs in a different but equivalent format)
The perturbed inputs in the latter two classes can be LLM-generated to rapidly create varied test sets.
Testing consistency guardrails
Use the LLM as a judge approach to review outputs to ensure that they adhere to any consistency guardrails you implemented, and include periodic human oversight of a random sampling. (You will also need to test for responses to adversarial prompts, such as jailbreaks and prompt injection attempts, but that is beyond the scope of this article.)
Detecting drift
Detecting drift requires continuous monitoring of performance over time. Rerun benchmarks and unit tests on a regular schedule and whenever underlying LLMs or package dependencies are updated. Where relevant, track the distribution of model outputs (e.g., classification probabilities) and investigate significant shifts. Track the statistical properties of incoming data, monitor shifts in mean or variance for numeric data, and examine frequency distributions for categorical data. Collect user feedback and analyze error patterns to detect concept drift. Analyze logs for changes in usage and any increase in the prevalence of out-of-scope queries your system detects.
Availability
The third key component of AI reliability is availability: The system must be online when needed and able to provide responses in a suitable timeframe. AI availability encompasses both infrastructure availability (being online when needed/promised) and latency (the time lag between initiating a request and receiving a response).
As with other aspects of AI reliability, availability requirements vary based on the use case. It’s acceptable if a free system used for entertainment is occasionally unavailable but not a paid system that customers rely on for time-critical analyses. A user may be happy to let a large reasoning model (LRM) run for 15 minutes while they go grab a coffee—allowing it to research, think, and code on its own—but if the AI is part of a pipeline that has to process millions of inputs per day, that won’t work.
Organizations deploying AI systems must carefully consider service reliability and uptime requirements. In pipelined systems, availability challenges can multiply. The cost of downtime can extend beyond immediate lost revenue, as customers may lose interest in systems with spotty availability and seek alternatives. For businesses offering AI-powered products to customers, meeting service-level agreement (SLA) commitments is crucial, making reliance on constrained upstream resources untenable. In LLM-based systems, API rate limits can restrict the availability of systems or pipelines that rely on the LLM outputs.
Latency is important because slow response times degrade the user experience in interactive applications and reduce throughput in batch processing pipelines. LLM latency is typically significantly higher than traditional AI model latency, often by orders of magnitude. RAG systems are further slowed by accumulating additional latency in the retrieval stage prior to the generation of a result.
The subsections below cover strategies for building highly available systems and for availability monitoring. For the purposes of this article, we will focus on the rate limit and latency aspects of AI availability; uptime and other basic infrastructure availability issues are not unique to AI systems and are covered in detail in many other resources.
Building for availability
LLMs are slow, but there are things you can do to make them faster. Here we explore some of your options for reducing LLM latency and dealing with rate limit challenges.
Most modern LLMs offer prompt caching through their APIs. Take advantage of this for the unchanging portions of your prompts (system instructions, examples, long context, etc.). When these are cached server-side, it cuts latency and reduces token costs and rate limit usage. Similarly, prompt compression techniques shorten prompts without sacrificing important content, enabling faster processing and lower costs.
Consider whether a smaller and faster model suits your needs or if you can route simple queries to faster, cheaper models while using state-of-the-art models for more complex tasks. For RAG systems, use a smaller, faster model for query embeddings even if you need a more expensive and slower model for the generation step.
When using smaller models, you can also consider the trade-offs of using an on-premises model: You eliminate network latency but often end up operating on less suitable hardware. That said, if you have hardware suitable for the model you want to run, you may achieve a speed benefit from the use of on-premises models. (With larger models, you probably gain more from a cloud provider’s superior hardware and batching than you lose in network latency.)
For cloud-hosted LLMs, choose a plan whose rate limits exceed your peak expected load by at least 50% to maintain your availability promises to your customers. Don’t plan based on average usage; plan for spikes during times of day or events that may cause greater need or interest in your user base.
For predictable workflows, you may be able to pre-generate partial responses during off-peak hours and cache them for future use. You may also benefit from implementing semantic caching of queries and responses, where you use embedding similarity to check if a new query is similar enough to a cached query to reuse the cached response, both saving time and staying under rate limits.
Additionally, streaming responses as they arrive gives users the impression of faster performance at no additional cost to you.
Availability testing and monitoring
Ongoing monitoring of latency will help you understand if and where your system is hitting bottlenecks. The primary metrics for LLM latency are:
- Time to first token (TTFT): The time from when the user submits a query until the first token of the response is communicated, which includes request queuing time, prefill time, and network latency
- Inter-token latency (ITL) and time per output token (TPOT): The throughput of tokens after the first. ITL is typically measured per token, while TPOT is the average ITL across all tokens. If ITLs vary widely, the user will experience choppiness even if the average is acceptable.
- Time to last token (TTLT) or end-to-end (E2E) latency: The time from when the user submits their query until the final token of the response is communicated
These are typically properties of the LLM you are using to back your system, but you should monitor it to ensure that you are getting the speed you are paying for in order to provide good service to your customers or maintain throughput in pipelined settings.
Additionally, you will need to monitor usage to see if you are approaching your rate limits, and if so, consider upgrading your plan.
How Patronus AI helps
AI reliability demands a proactive and ongoing commitment; it is important to have a plan for ongoing monitoring and testing. Patronus AI offers a platform that enables your engineering team to test, score, and benchmark LLM performance on real-world scenarios, generate adversarial test cases at scale, monitor hallucinations, and track experiments and deviations from your baseline throughout your AI development and deployment lifecycle.
In this section, we offer examples of how Patronus AI’s Lynx RAG hallucination evaluator and its Percival agentic AI debugger can make improving your AI reliability easier.
Using Lynx to test for RAG faithfulness
Patronus offers API access to many of its tools. To get an API key, sign up for an account at app.patronus.ai if you don’t already have one, then click on API Keys in the navigation bar.
Note: The code in this section can be found in this Google Colab Notebook.
First, install the required libraries:
!pip install opentelemetry-exporter-otlp==1.37.0
!pip install opentelemetry-api==1.37.0 opentelemetry-sdk==1.37.0
!pip install opentelemetry-exporter-otlp-proto-grpc==1.37.0
!pip install opentelemetry-exporter-otlp-proto-http==1.37.0
!pip install -qU patronus
Then import Patronus and set your API key:
import patronus
from google.colab import userdata
PATRONUS_API_KEY = userdata.get('PATRONUS_API_KEY')
We’re going to use Lynx to test the faithfulness of two different responses to the same question and context, both of which are true but only one of which is faithful to the context. (We used Claude Sonnet 4.5 to write the context.)
task_input = "What do horses and whales have in common?"
task_context = """Mammals are a special group of animals that share
some important things in common. All mammals are warm-blooded,
which means their bodies stay warm even when it's cold outside.
Mammal mothers give birth to live babies instead of laying eggs,
and they feed their babies milk from their bodies. Mammals also
have hair or fur at some point in their lives. There are many different
kinds of mammals all around us! Dogs, cats, and horses are mammals. Humans
are mammals too! Even animals that might surprise you are mammals - like
bats that can fly and whales that live in the ocean. Even though mammals
can look very different from each other and live in different places, they
all share these special features that make them part of the mammal family."""
task_output_1 = "Horses and whales are both mammals."
task_output_2 = "Horses and whales both have four-chambered hearts and breathe oxygen through lungs."
Run the following to set up the Lynx hallucination evaluator, which is designed to assess whether a task output is faithful to a provided context or if it hallucinates a different answer (which may still be true based on the model’s parametric knowledge, as in our example).
from patronus import init
from patronus.evals import RemoteEvaluator
# Initialize with your API key
init(api_key=PATRONUS_API_KEY)
# Create a Lynx hallucination evaluator
hallucination_check = RemoteEvaluator("lynx", "patronus:hallucination")
Here we test a faithful triplet:
# Run the evaluation with a faithful output
result = hallucination_check.evaluate(
task_input=task_input,
task_output=task_output_1,
task_context=task_context
)
result.pretty_print()
Lynx provides the following assessment, indicating that the triplet passes the test because the answer directly aligns with the information provided in the context:
explanation: '''The context explicitly states that horses and whales are both mammals.'',
''The context provides a list of characteristics that all mammals share, such as
being warm-blooded, giving birth to live babies, and having hair or fur at some
point in their lives.'', ''The context mentions specific examples of mammals, including
horses and whales, to illustrate that these animals are indeed mammals.'', "The
answer ''Horses and whales are both mammals'' directly aligns with the information
provided in the context.'''
explanation_duration: PT0S
metadata:
confidence_interval: null
extra: null
positions:
- - 0
- 35
pass_: true
score: 1.0
tags: {}
When we run the test again with task_output_2, Lynx correctly marks this as a failure because the answer introduces specific details about the heart and respiratory system that are not supported by the context:
explanation: '- The context provided does not mention anything about the heart structure
or the respiratory system of horses and whales.
- The context only discusses general characteristics of mammals, such as being warm-blooded,
giving birth to live young, and having hair or fur.
- The answer introduces specific details about the heart and respiratory system,
which are not supported by the context.'
explanation_duration: PT0S
metadata:
confidence_interval: null
extra: null
positions:
- - 54
- 82
- - 28
- 49
pass_: false
score: 0.0
tags: {}
Using Percival
For agentic AI systems, Patronus AI has developed Percival, an agent capable of suggesting optimizations and detecting over 20 failure modes in your agent traces. To demonstrate the use of Percival, we created a simple LangGraph application with three agents to take a customer query and do the following:
- Classify and route the query to one of three sections of the (synthetic) customer service knowledge base: billing, technical, or general
- Retrieve the three most relevant documents from the section of the knowledge base selected by the routing agent
- Generate a response to the query using Mistral using the most relevant documents retrieved by the retrieval agent as context
Note: The code in this section can be found in this Google Colab Notebook.
After setting up the LangGraph app, we initialize Patronus with the appropriate integrations:
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry.instrumentation.threading import ThreadingInstrumentor
from opentelemetry.instrumentation.asyncio import AsyncioInstrumentor
import patronus
# Retrieve the Patronus API key
PATRONUS_API_KEY = userdata.get('PATRONUS_API_KEY')
# Initialize Patronus with automatic instrumentation
patronus.init(
api_key=PATRONUS_API_KEY,
project_name="customer-support-demo",
integrations=[
LangChainInstrumentor(),
ThreadingInstrumentor(),
AsyncioInstrumentor(),
]
)
We then wrap the app execution function with the Patronus traced decorator:
@patronus.traced("customer-support-demo")
def run_support_query(query):
"""Run a single customer support query through the pipeline."""
result = app.invoke({"query": query})
return result
Then we run through a set of test queries:
# Now run the test queries
for query in test_queries:
print(f"Query: {query}")
result = run_support_query(query)
print(f"Category: {result['category']}")
print(f"Response: {result['response']}\n\n")
The agent system was intentionally designed to have several faults, providing an opportunity to demonstrate some of the types of feedback Percival can provide. For instance, the routing agent is designed to route half of very short queries to “general” regardless of the content of the query:
# Flaw 4: Short queries default to general (lose context)
if len(query.split()) <= 3:
if random.random() < 0.5:
return ("general", 0.55, "Short query, defaulting to general")
Percival picked up on this flaw and provided the following feedback:

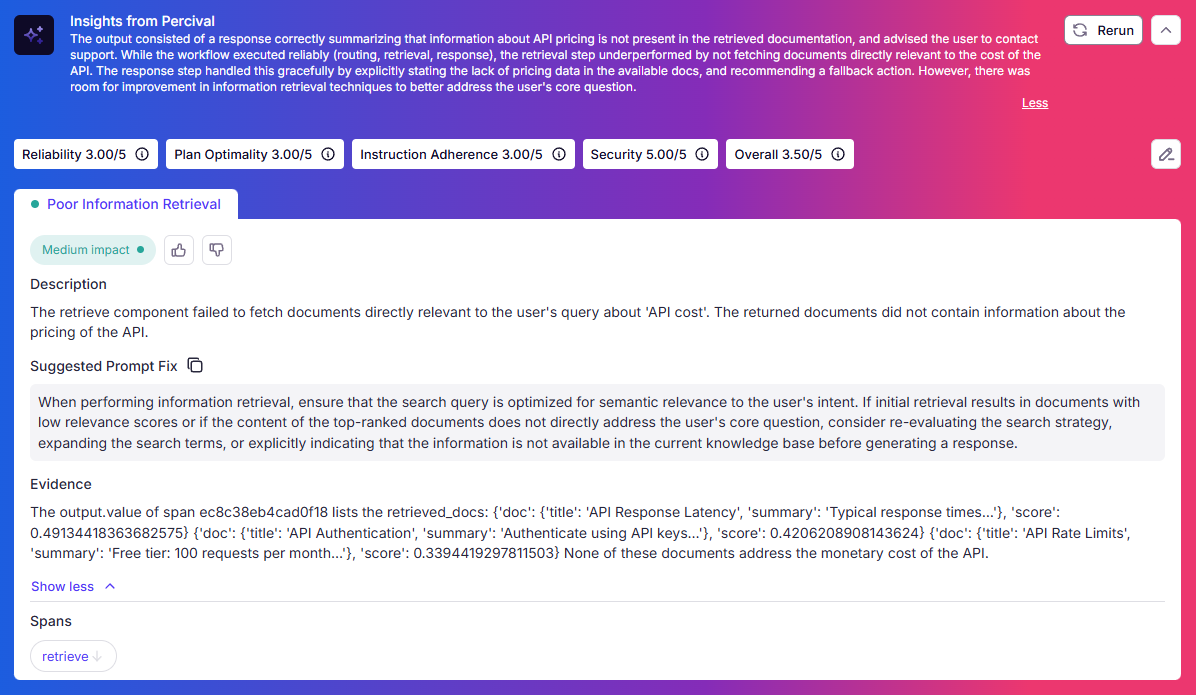
In another instance, we asked the system for information not included in the knowledge base. Percival noted the poor information retrieval and also the response agent’s correct behavior in admitting that it did not have the information:
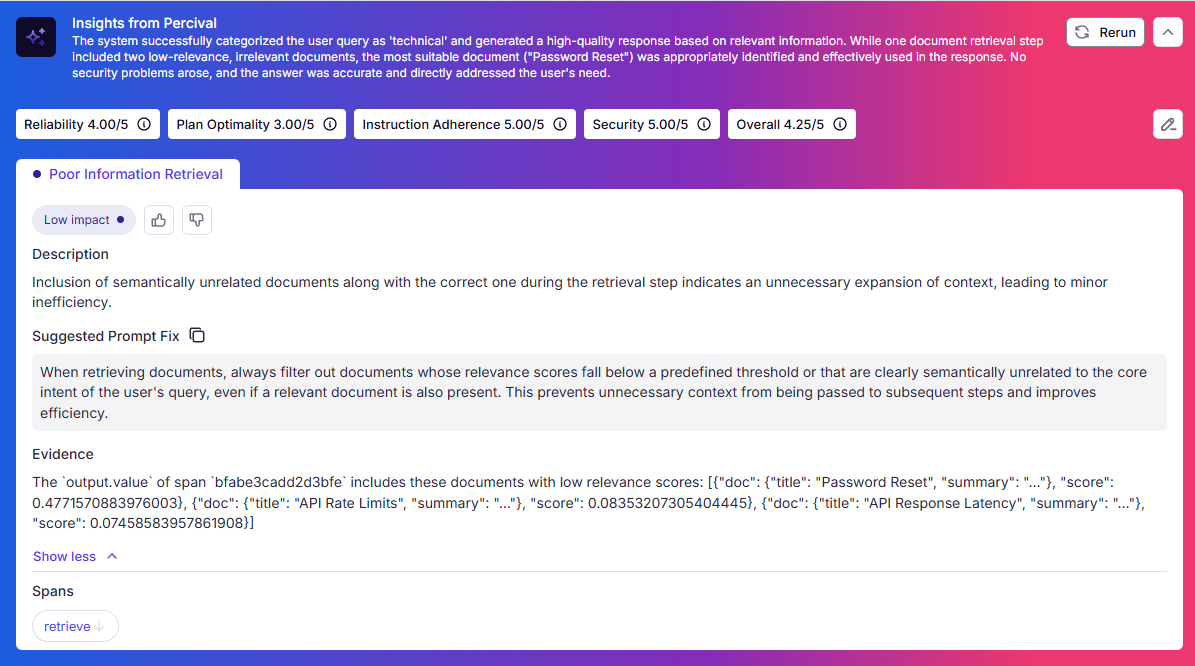
Percival was also able to give advice for improving the efficiency of the response agent by not passing it documents with very low relevance scores to prevent unnecessary context from being passed to the LLM for generation, which speeds up the execution and potentially reduces costs:
Percival’s ability to analyze your agent traces and identify errors and inefficiencies can be a great help in improving the reliability of your agentic AI systems.
{{banner-dark-small-1="/banners"}}
Conclusion
Delivering reliable AI requires careful attention to correctness, consistency, and availability from day zero. However, there are trade-offs to consider: Greater correctness may come at the cost of higher latency, for example, so you will need to understand your specific use case’s requirements and prioritize accordingly. Clearly defining your reliability requirements up front lets you make informed decisions about where to invest your resources and how to align your reliability trade-offs with your business objectives.
The AI reliability field is evolving rapidly, with new tools, techniques, benchmarks, and best practices arising constantly. Foundation models continue to improve, but you must also remain vigilant to the risk that an “improved” model may cause a degradation to your tool or pipeline. In return for your commitment to reliability, you will be rewarded with increased user trust, better compliance, and more successful AI deployments.