

Introducing Generative Simulators: Autonomously Scaling Environments for Agents
Generative Simulators: A New Class of Autonomously Scaling RL Environments
We are building the world’s first autonomously scaling environments to advance AGI. Come join us.
The Evolution of AGI Training: From Static Datasets to Generative Environments
Modern AI systems are most commonly evaluated on static benchmarks and environments, but these are susceptible to reward-hacking, contamination, leakage, and saturation. Today, most RL environments are fixed collections of domain specific tasks, such as leetcode-style problems and customer service queries. They help assess and improve basic tool use, environment exploration and instruction following capabilities of models. However, with the recent improvements in models, these benchmark environments have come to saturate, such as Tau2-Bench getting nearly saturated by GPT-5.2. This saturation is due to the lack of plasticity of these environments.
To address this problem, we introduce Generative Simulators, adaptive environments that jointly co-generate tasks, world dynamics, and reward functions. We believe that generative simulators constitute the foundational infrastructure for self-adaptive world modeling, extending beyond reinforcement learning algorithms and beyond human-curated datasets.
Generative Simulation for Auto-Scaling RL Environments
Generative Simulators are centered on the concept of plasticity. We have built a multi-agent architecture capable of producing challenging, diverse tasks and tool sets with minimal specification.
- Once a task's difficulty and simple configurations have been specified, our Task Generation module sequentially creates tasks that satisfy these constraints, coupled with task timelines that are reflective of difficulty (e.g. difficult tasks should take longer to execute).
- A set of tools is selected based on the task difficulty, with more challenging tasks requiring more extensive tool sets.
- Given the generated tasks, we perform curriculum-based task filtering based on current agent's capabilities and required difficulty levels and couple these tasks with tool stacks of appropriate complexity.
- These task-tool tuples are then used to evaluate and train an agent. The agent then executes the tasks, producing a series of output trajectories.
- These trajectories are finally scored using a reward function to populate the final evaluation report. In an ideal scenario, this reward function is co-generated with the task definition but is ensured to be verifiable.
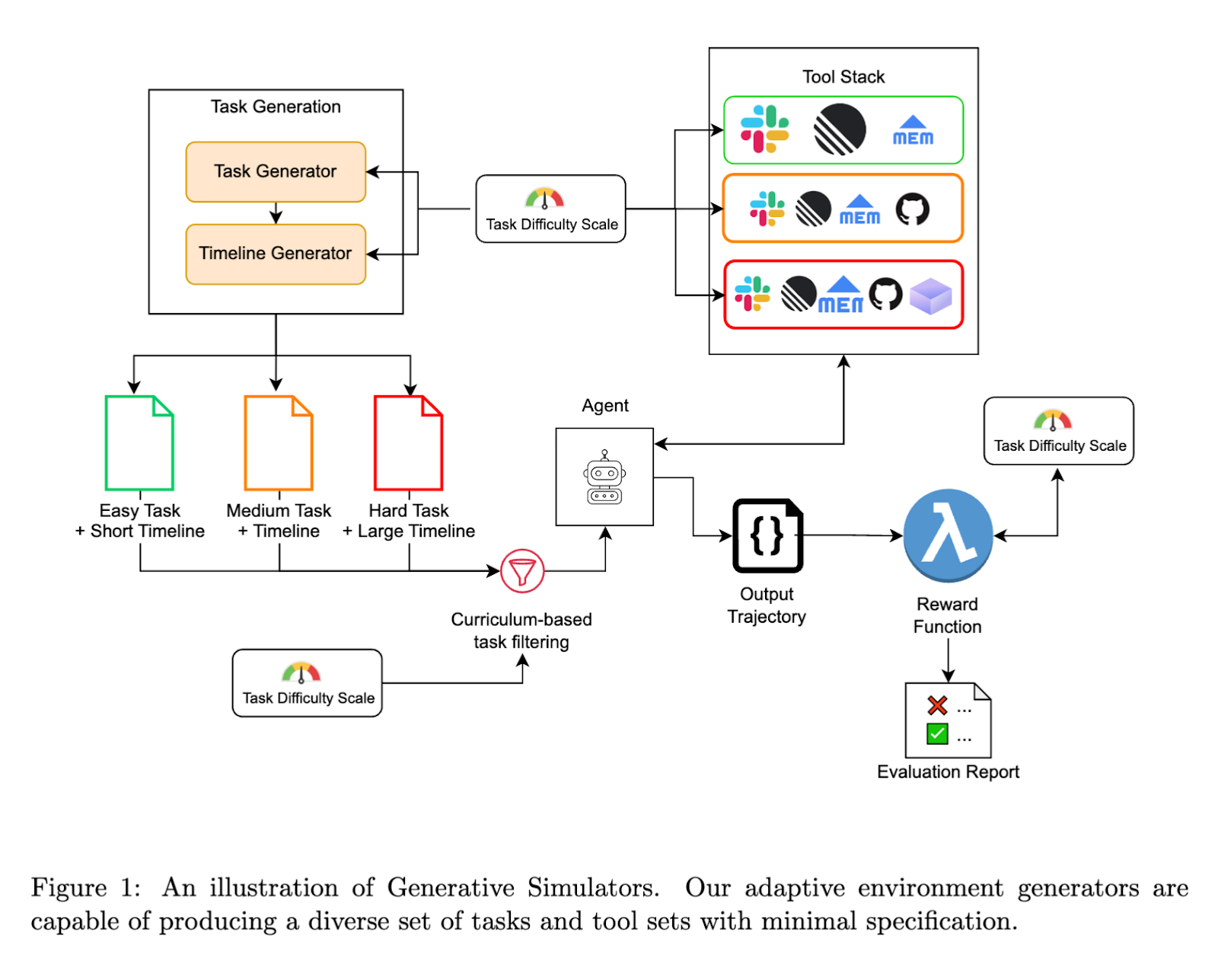
In such a system, the three components of task generation, world tooling and reward modeling can be independently or jointly made more difficult, which helps scale difficulty for problematic areas of the model specifically. This provides the required plasticity in the world. Furthermore, with this design, the domain specificity of an RL environment can be naturally altered by adding, removing or swapping out toolsets specific to a domain. For example, adding a browser use toolset to an existing SWE-Bench like task can help extend the domain-set to frontend development situations where the agent is required to debug visually using the browser tools.
Our History From Evaluation to Generative Simulators
Our work on generative simulators emerged from a sequence of research questions about how agent behavior can be meaningfully evaluated in realistic settings. Early evaluation research revealed that many critical failures such as hallucinations, incorrect tool use, loss of context only arise through interaction. Single-turn evaluation masked these failures.
Our future direction in Generative Simulation is a culmination of our work from the past 2 years:
- FinanceBench: the first large-scale Finance question-answering benchmark over SEC 10ks and 10Qs. FinanceBench is the standard for agent evaluation in Finance, and is now used as an environment by post-training teams in all major labs and thousands of academic institutions worldwide. We are continuing to build Finance RL environments.
- Lynx: the first open source hallucination detection model, outperforming closed source LMs including GPT-4o, Claude-3-Sonnet.
- GLIDER: We trained a reward model to grade LLM interactions and decisions using explainable ranking. GLIDER is deployed at Fortune 500s across the world to provide rubric-based rewards at scale on AI system outputs.
- Percival: the first agent-as-a-judge capable of evaluating multi-step workflows with a memory module and human-guided rubrics. While most environments today rely on verifiable rewards, we believe that the future of training and evaluation will require human-aligned semi-verifiable and non-verifiable rewards.
- BLUR (ACL 2025): BLUR introduces a set of 573 real-world questions that demand searching and reasoning across multi-modal and multilingual inputs, as well as proficient tool use. Humans easily ace these questions (scoring on average 98%), while the best-performing system scores around 56%.
- TRAIL: Benchmark for agentic reasoning and trace evaluation with 20+ failure types and human-labeled execution paths; SOTA models score <11%
- Memtrack (NeurIPS SEA Workshop 2025): Memtrack is an agent memory benchmark where an agent must navigate a real world workplace with communication and planning tools such as slack and Linear. We found that capabilities such as memory cannot be evaluated without environments that unfold over time and require persistent state.
Together, our research revealed a unifying insight: evaluation, learning, and oversight converge when environments are interactive, stateful, and adaptive. Generative simulation is the culmination of our past work on benchmark design, synthetic dataset generation, LLM and agent judges and reward model training - components that are necessary for auto-scaling environments.
The Road Ahead
We are partnering with model developers to develop world class RL environments. With generative simulation, we have constructed hyperrealistic, auto-scaling worlds that are complex and learnable, to train agents to perform real world job functions ranging from equity research analysts to product engineers.
We are just scratching the surface of AGI capabilities. There are many open research questions that we are tackling. In our path to AGI, environments are the new oil.
We have grown 15x in revenue this year. We doubled in size last month. We are scaling quickly across all fronts – research, engineering, operations. We are hiring post-training and evaluation researchers excited about open research challenges in reward design, auto-scaling tasks and solving the generalization problem in RL training. We are a team of evaluation obsessed researchers and engineers. We fundamentally want to understand how agents - and humans - reason, learn and adapt in an ever evolving world.
If this resonates with you, reach out to us to chat.
Paper: https://patronus.ai/generative-simulators
—
Patronus AI Team

