

LLM Post Training: Tutorial & Examples
Modern large language model (LLM) development is typically divided into two phases. The first is pre-training, where a model learns to predict the next token (word, subwords, or characters) using enormous amounts of text to acquire broad knowledge. This produces a general-purpose base model.
The second phase is post-training, during which the base model is further trained on specialized, curated datasets to learn specific behaviors, such as following instructions or adhering to certain styles.
Post-training uses far fewer tokens and can be done much faster and cheaper than pre-training, yet it is critical for aligning the model with desired use cases.
This article provides a practical guide to LLM post-training: what it is, when to use it, requirements, and three approaches. By the end, you should be able to decide if post-training is right for your project, choose the appropriate method, prepare the necessary data, and implement post-training examples in Python.
Summary of key LLM post-training concepts
What is LLM post-training?
LLM post-training (also called instruction tuning or alignment tuning) is the process of adapting a pre-trained base model into an instruction-following or any other custom response generation model that better follows user instructions and exhibits desired behaviors.
In post-training, the model learns from curated data in dialogue, feedback, or task-specific formats, rather than the raw text it saw during pre-training. For example, a base model might know many facts and language patterns but respond to a question by simply completing the sentence. In contrast, after post-training, the model answers the question directly and helpfully.
Post-training bridges that gap by imprinting new behavior onto the model with a relatively small, high-quality dataset. This phase uses far fewer tokens than pre-training (often orders of magnitude less data), but demands careful data selection and evaluation to steer the model in the right direction without inadvertently degrading its other skills.
Since post-training is much faster and cheaper than pre-training, it’s an attractive option for model customization. However, it requires the right approach and careful execution to succeed.

Requirements for LLM post-training
Effective post-training has three key requirements.
Algorithm-data alignment
Each post-training method expects data in a particular shape. Before you begin, ensure you can gather or construct the appropriate dataset for the approach you plan to use.
Libraries and tools
There are established libraries and frameworks to help implement post-training techniques. A popular choice is Hugging Face’s TRL (Training Reinforcement Learning) library, which provides implementations for common algorithms, including SFT, DPO, and PPO-based RL. Other popular libraries include RAGEN, NeMO RL, ROLL, etc.
Evaluation strategy
After post-training, a model may become better at the targeted task but worse at another task, or it may forget previously learned behavior, a phenomenon known as catastrophic forgetting. You should also monitor a post-trained model for overfitting, where the model performs well on your fine-tuning data but fails to generalize to broader tasks. To catch these issues, use a broad evaluation suite. This can include automated metrics or benchmark tests for general capabilities (such as knowledge questions, coding tests, and math problems), as well as comparative evaluations, such as having an LLM judge outputs (as done in chatbot arenas or MT-Bench).
When to use post-training
Use post-training when your use case requires a model that consistently adheres to a comprehensive set of instructions or excels in a specific capability. For example, aligning a model with a company’s extensive style guide or teaching it to perform multi-step reasoning in a specialized field would be very hard to achieve with prompts alone. Post-training provides a way to incorporate these behaviors into the model itself.
In general, if you find yourself writing the same instructions into every prompt or correcting the model’s outputs in a specific way repeatedly, that’s a good indication that a fine-tune could make your life easier.
Increasingly, teams are also adopting hybrid approaches, such as combining Retrieval-Augmented Generation (RAG) with post-training. In this setup, RAG provides access to up-to-date or proprietary knowledge, while post-training ensures the model interprets and responds to that knowledge in a consistent, policy-aligned manner.
When not to use post-training
Not every situation calls for custom post-training of an LLM. In some cases, simpler techniques are sufficient or more appropriate.
Simple policy or style changes
Don't use post-training for simple policy or style changes. If you only need the model to follow a few straightforward instructions or adopt a slightly different tone, you can achieve this by writing a good prompt or using a few-shot examples.
Up-to-date facts or domain knowledge
Post-training is not the most effective way to impart new factual knowledge to an LLM, especially when the knowledge base is large or rapidly changing. For fresh or extensive information, such as new organizational policies or a large proprietary document corpus, a retrieval-augmented generation (RAG) approach is often more effective: maintain a knowledge database and have the model retrieve relevant information at query time.
Supervised fine-tuning (SFT)
SFT is the most straightforward post-training method. It uses imitation learning: you provide the model with example prompts and ideal responses, and train it to imitate them.
Technically, the loss function is the familiar cross-entropy (negative log-likelihood) on the target output tokens given the prompt. By minimizing this loss over a dataset of (prompt, desired response) pairs, the model learns to produce the desired response when it sees a similar prompt.
SFT is highly effective for introducing new behaviors in a model. For instance, if you have a pre-trained LLM that is just continuing your sentence or outputting generic text, a round of SFT on a few thousand high-quality QA or dialog pairs can transform it into a usable chat model.
Use cases
Common use cases for supervised fine-tuning include:
Converting a base model into an instruction or chat model. SFT is what made GPT-3 into InstructGPT. If the base model is not already tuned to follow user instructions, SFT with a general instruction-following dataset is the go-to solution.
Overhauling the assistant’s style, tone, or format. If you need the model to adopt a specific voice (say, a friendly customer support agent) or to follow strict formatting (like always answering in JSON), you can fine-tune on examples that demonstrate the desired style. This also applies to tool-use conventions, e.g., fine-tuning a model to use a <search> command in its responses when appropriate.
It is important to note that simple tone or phrase tweaking, such as asking the model to be more polite, can he handled through prompt engineering with a few-shot examples. SFT is better suited when the style change is systematic and domain-specific, such as teaching a model to consistently write medical reports, legal summaries, or technical documentation in a precise, structured format.
Distilling a larger model’s abilities into a smaller model. SFT can serve as a knowledge distillation method where you generate a large set of Q&A or dialog responses from a powerful teacher model, then fine-tune a smaller model to reproduce those responses. This way, the smaller model learns the patterns of the larger one.
How to prepare data for SFT
Your training data should be a collection of high-quality prompt–response pairs that exemplify exactly the behavior you want the model to learn. Quality is far more important than quantity here. The reason is simple: the model tries to imitate whatever you give it, so bad examples will teach it bad habits. It’s better to have a small dataset of all great responses than to include inconsistent or poor ones.
There are a few effective strategies to get good SFT data:
- Manual writing or human labeling: If you have domain experts or annotators, they can craft prompt–response pairs demonstrating the desired answers. This ensures quality but can be slow and expensive.
- Distillation from a stronger model: Use a more capable model to generate responses to a list of prompts, and use those generations as your fine-tuning targets. You might still need to review/edit them, but this can quickly produce a large aligned dataset.
- Best-of-N sampling: Take your current model (or another model) and have it produce N different responses to each prompt, then pick the best one (using either a reward function or human judgment) as the target. This “rejection sampling” approach can yield higher-quality responses from the model itself.
- Filtering a large dataset: If you have a large pool of candidate Q&A pairs from somewhere (open-source datasets, or logs, etc.), apply filters to select only the highest-quality and most diverse examples.
When curating SFT data, ensure you cover a diverse set of prompts that reflect the variety of situations your model will encounter, so it doesn’t learn a very narrow behavior. And always double-check that the “gold” responses in your data are truly ones you would be happy with the model saying, because the model may repeat them almost verbatim in some cases.
Pros
Simplicity: It’s conceptually simple and easy to implement with standard training libraries. You’re essentially doing the same supervised learning procedure used in many other machine learning tasks.
Powerful behavior shifts: SFT can achieve significant changes in the model’s behavior (new capabilities or a new persona) with relatively little data and time.
Cons
Risk of narrow tuning: If your SFT dataset is narrow (limited topics or styles), the model might become too specialized and perform worse on inputs outside that distribution.
Requires careful evaluation: You need to evaluate the model on a wide range of tasks after SFT to detect any unintended performance degradation. SFT can inadvertently degrade skills that were not represented in the fine-tuning data.
Requires retraining in case of behavioural changes: Not suitable for changing or adaptable domains. You might need to retrain your model if new model behaviour is required.
Implementing supervised fine-tuning
This example uses the Hugging Face Transformer Reinforcement Learning (TRL) library for LLM post-training. You can find all the codes in this article in this Google Colab Notebook.
Import & install required libraries
The following script installs the TRL library.
!pip install trl==0.21.0Import model and tokenizer
The script below imports the required libraries and modules. The “SFTTrainer” and “SFTConfig” classes allow you to post-train an LLM using SFT techniques. In addition, import the “AutoModelForCasual” LLM and “AutoTokenizer” libraries to load LLMs and their tokenizers from Hugging Face.
import torch
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset, Dataset, Value
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer, SFTConfig
Define a helper method that loads the LLM and its tokenizer from Hugging Face. Define a chat template for the tokenizer if it doesn’t already have one.
The role of a chat template is to convert user conversations into a structured format for LLM training.
def get_model_and_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.to("cuda")
if not tokenizer.chat_template:
tokenizer.chat_template = """{% for message in messages %}
{% if message['role'] == 'system' %}System: {{ message['content'] }}\n
{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n
{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>
{% endif %}
{% endfor %}"""
if not tokenizer.pad_token:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
model, tokenizer = get_model_and_tokenizer("Qwen/Qwen3-0.6B-Base")
The above script imports the “Qwen3-0.6B-Base” LLM, a base LLM without any fine-tuning or post-training. You can use any other LLM if you want.
{{banner-large-dark-2-rle="/banners"}}
Generating model response before SFT
Next, define a helper function that receives a model (LLM), a tokenizer, a user message, and a system prompt. It converts the user message and system prompt into a format defined in the tokenizer. The tokenizer then tokenizes the text (converts it into numeric IDs), which it passes to the LLM to generate a response. The LLM response is decoded back to text format and returned to the calling function.
def generate_single_responses(model, tokenizer, user_message, max_new_tokens=1000, system_prompt = None):
messages = []
if system_prompt:
messages.append(
{"role": "system", "content": system_prompt}
)
messages.append(
{"role": "user", "content": user_message}
)
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False,
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Recommended to use vllm, sglang or TensorRT
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
input_len = inputs["input_ids"].shape[1]
generated_ids = outputs[0][input_len:]
response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()
return response
Ask a question to test.
query = "What are some causes of brain tumour?"
response = generate_single_responses(model, tokenizer, query)
print(response)
Output:
⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙
The above output shows that the base model generated random tokens. This is because, by default, it may not have the knowledge to answer the user’s question, and secondly, the base model is not trained to expect queries in the instruction-following format as defined in the tokenizer.
You have to fine-tune the base model to follow the instruction-following format defined in the tokenizer and generate logical responses.
Perform SFT and generate response
For SFT, you need a dataset containing input-output pairs. This example uses the medical-question-answering-dataset from Hugging Face. The dataset consists of medical questions and corresponding answers. The following script imports the dataset.
train_dataset = load_dataset("Malikeh1375/medical-question-answering-datasets", 'all-processed')["train"]
train_dataset.to_pandas().head(5)
Output:

Next, convert the dataset to the format defined earlier for the tokenizer, as shown below.
def preprocess_medical_chat(example):
# Build chat-style structure
messages = [
{"role": "user", "content": example["input"]},
{"role": "assistant", "content": example["output"]},
]
# Apply chat template (this formats it as the model expects)
formatted_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False # for training
)
# Tokenize the formatted text
tokenized = tokenizer(
formatted_text,
truncation=True,
padding="max_length",
max_length=1024, # since medical texts are long
)
# Labels mirror input_ids for causal LM training
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
train_dataset = train_dataset.select(range(200))
tokenized_dataset = train_dataset.map(preprocess_medical_chat, batched=False)
Finally, define training configurations using the SFT config class and start training with the SFTTrainer class. You can check out the SFT trainer documentation for more details on the parameters.
# SFTTrainer config
sft_config = SFTConfig(
learning_rate=8e-5,
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
gradient_checkpointing=False,
logging_steps=5,
report_to="none" # do not report to huggingface or weights and biases
)
sft_trainer = SFTTrainer(
model=model,
args=sft_config,
train_dataset=tokenized_dataset,
processing_class=tokenizer,
)
sft_trainer.train()
Output:
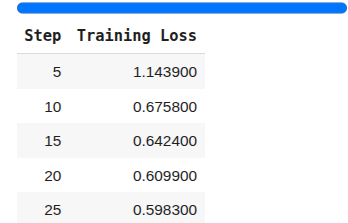
Once the post-training is complete, you can use the post-trained model to ask the same question as before.
query = "What are some causes of brain tumour?"
response = generate_single_responses(sft_trainer.model, tokenizer, query)
print(response)
Output:

The above output shows that the base LLM has learned to follow instructions and generate logical responses to complex queries.
Direct preference optimization (DPO)
In DPO, you train the model using comparisons between a preferred response and a dispreferred (rejected) response for the same prompt. Instead of imitating an absolute answer, the model learns the relative ranking: “response A is better than response B for this prompt.” The training objective then pushes the model’s output distribution toward the preferred response and away from the dispreferred one.
This approach is particularly useful for making fine-grained adjustments to behavior. Rather than modifying the model’s behavior from scratch, you start with a model that’s already decent, typically one that has already undergone supervised fine-tuning (SFT), and apply DPO to correct or refine specific aspects. Starting from a raw base model may yield poor results, since DPO relies on the model already producing coherent, instruction-following responses.
For example, if users prefer the assistant to say “I am your AI assistant” instead of “I am your assistant,” you can create a comparison where the former is the preferred response and the latter is the dispreferred. The DPO teaches the model that preference.
DPO use cases
The following are some of the use cases for DPO:
Tuning identity, voice, or policy compliance. For instance, updating the model’s persona or ensuring it follows certain guidelines. For example, you can fine-tune on a set of prompt-response pairs, where one version follows the policy and the other doesn’t.
Nudging the model away from bad habits. If an instruction model has a tendency you don't like, you can apply DPO with examples showing the preferred alternative. It’s often faster to gather a handful of comparisons addressing a specific model behaviour than to rebuild a whole SFT dataset.
Pros
Targeted improvement: DPO is great for targeted fixes. You don’t have to retrain the model on everything, just on the specific distinctions you care about.
Data efficiency and speed: It often requires less data than a full SFT to correct a behavior, and you can iterate quickly by adding more comparison examples as you observe new issues.
Offline and reward-free training: Unlike reinforcement learning methods, DPO operates entirely offline, requiring no new rollouts or separate reward model training. This makes it easier to implement, more stable, and less resource-intensive while still leveraging preference data effectively.
Cons
Sensitive to data biases: The model’s adjustment is only as good as the comparison data. If the preferences are noisy or inconsistent, the model may learn the wrong thing. Labeler bias (what one person thinks is “good”) can creep in.
Potential overfitting to small changes: If the comparisons aren’t carefully curated, the model might pick up on unintended patterns (like always avoiding a certain word that appeared in all the bad examples, even when it might be okay). Ensuring a clean, diverse comparison set is crucial.
Implementing DPO
The Hugging Face TRL library provides the “DPOTrainer” and “DPOConfig” classes to post-train an LLM via direct preference optimization.
from trl import DPOTrainer, DPOConfig
How to prepare data for DPO
You will need to construct comparison pairs for training. Each pair consists of a prompt and two responses: one labeled as the better (preferred) answer and one as the worse (non-preferred). There are a couple of ways to get these:
- Manual curation (with human labels): Have human reviewers review model outputs and mark which answer they prefer. You can generate candidate responses by prompting your current model or different models, then ask humans to choose the better one for each prompt. This yields high-quality preference data but requires human effort.
- On-policy generation: Another approach is to use your model to generate multiple responses for each prompt (say, 5 different answers), then automatically pick the best and worst. This is faster, but be careful because an automated process might introduce bias if, for example, it always picks responses with a certain keyword as “best.”
As with SFT, the quality of comparisons matters more than sheer quantity. A few hundred well-chosen comparison examples can be enough to fine-tune a specific behavior.
Generating model response before DPO
For DPO, you can use an instruction-following mode, since you want the model to be post-trained to pick a preferred response. This example uses the “Qwen2.5-0.5B-Instruct” model.
The following script generates the answer to a user query before DPO post-training.
model, tokenizer = get_model_and_tokenizer("Qwen/Qwen2.5-0.5B-Instruct")
query = """What is the diagnosis for a man coming from the mountains, whose wife died 6 months ago, and who reports that his wife appeared to him asking him to join her?
"""
response = generate_single_responses(model, tokenizer, query)
print(response)
Output:

Next, post-train the LLM to generate a better response or one you prefer.
Perform DPO and generate a response
You need a dataset containing chosen and rejected response pairs. To do so, we can use the dpo-medical-o1-synth dataset from Hugging Face. The script below imports the dataset.
dpo_dataset = load_dataset("EliasHossain/dpo-medical-o1-synth")["train"]
sample_dataset = dpo_dataset.to_pandas().head(200)
sample_dataset.head(3)
Output:

You do not need to format the data, as it is already in the format the “DPOTrainer” expects. The following script trains the LLM. For details on parameters, check the DPO trainer's official documentation.
dpo_dataset = dpo_dataset.select(range(200))
config = DPOConfig(
beta=0.2,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
learning_rate=5e-5,
logging_steps=5,
report_to="none"
)
dpo_trainer = DPOTrainer(
model=model,
ref_model=None,
args=config,
processing_class=tokenizer,
train_dataset=dpo_dataset,
)
dpo_trainer.train()
Output:
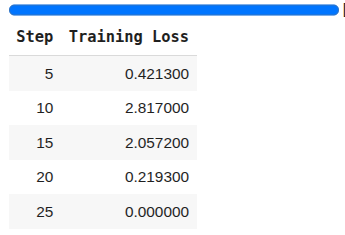
Now, if you ask the same question about a patient’s diagnosis, you will see a better, more formulated response with concrete reasons.
query = """What is the diagnosis for a man coming from the mountains, whose wife died 6 months ago, and who reports that his wife appeared to him asking him to join her?
"""
response = generate_single_responses(dpo_trainer.model, tokenizer, query)
print(response)
Output:

Online reinforcement learning (RL)
The core idea of online reinforcement learning is to set up a feedback loop: have the model generate responses, evaluate each response with a reward function, and then update the model to increase the chances of high-reward responses. This process is repeated iteratively, with the model continuously generating new data and learning from it in an on-policy fashion.
In online RL, unlike supervised methods, the model is not told the exact correct answer. Instead, it explores various outputs and receives feedback as a scalar reward. The training algorithm then adjusts the model to maximize this reward over the distribution of prompts.
A major advantage of RL is that you can define highly flexible, outcome-driven objectives. For example, you can reward a chain of thought that leads to a correct math answer, or penalize a behavior like refusal to follow instructions. This makes RL particularly powerful for improving specific capabilities, such as multi-step reasoning, coding (where passing unit tests is the reward), or factual accuracy (where a reward model might judge correctness).
Before diving further, it’s important to note the distinction between online and offline RL in this context. Online RL means the model generates fresh responses during training to learn from; it’s a live loop where each update is based on newly generated examples. Offline RL means you have a fixed set of (prompt, response, reward) tuples and train on them without generating new data. In practice, nearly all RL applied to LLMs is online
Online RL use cases
Online RL is best suited for situations where you have a clear way to evaluate success for a given output. For example:
- Training a model to solve math problems by rewarding it only when it gets the correct answer. This requires being able to automatically check the answer.
- Improving a coding assistant by using unit tests as a reward signal. The model gets a positive reward when the code it writes passes the tests.
- Enhancing factual accuracy by training with a reward model that scores outputs higher when they are truthful or match a knowledge source.
In short, if you have a well-defined metric or gold-standard check for the task, RL can directly optimize the model for it. RL is also useful for long-horizon tasks or agent behaviors, where the model’s sequence of actions needs to yield a good final outcome.
Pros
Strong capability gains: With a well-shaped reward, RL can dramatically improve the model’s performance on that metric or task.
Focused training that preserves other skills: Since RL is not simply mimicking new data but optimizing a reward, it tends not to override the model’s behavior on unrelated inputs as much as a naive SFT might.
Cons
High implementation complexity: Online RL training is the most complex to set up. You need to manage a generation loop, possibly train a reward model, and tune a variety of hyperparameters to keep training stable.
Reward hacking: The model might find loopholes to get a high reward in unintended ways. This is a classic RL problem. If the reward is not perfectly aligned with what you really want, the model may exploit the difference.
Preparing data for online RL
Even though RL is “on-policy” (creating data on the fly), you still need some preparations before you can start RL.
Prompts & environment setup
This could be a list of user queries, problems, or scenarios that represent the tasks or behaviors you want the model to learn. It’s essential to ensure diversity in your prompts, covering various topics, formats, and difficulty levels, to prevent the policy from overfitting to a narrow domain or memorizing patterns from a limited set of examples.
Reward function
There are two broad categories of rewards:
- Learned rewards: usually based on human-labeled data. For instance, you might have humans rank answers for helpfulness, then train a reward model to imitate those rankings.
- Verifiable rewards: They work only for tasks with a clear correctness measure. Examples include comparing a generated answer to a known correct answer (for QA or math problems) or running a unit test on generated code.
In practice, you might combine both: use a learned reward model for general qualities and supplement with specific checks for things like safety or factuality.
With prompts and a reward in place, the training loop looks like this: for each prompt, have the model:
- Produce an output
- Measure the reward
- Update the model parameters using an RL algorithm (also known as a policy) to increase the probability of that output (or similar outputs).
- Repeat from step 1.
Policy optimization algorithm
The two common algorithms for RL learning are PPO (Proximal Policy Optimization) and GRPO (Group Regularized Policy Optimization). Both aim to maximize the rewards while keeping the model’s changes constrained.
PPO uses a reward model and a value function to estimate advantages at the token level, providing fine-grained training signals but requiring substantial memory and computational complexity.
GRPO, a newer approach, simplifies this by treating the entire sequence’s reward as a single signal applied to all tokens in that sequence. This can be more stable when rewards are binary or sparse (like success/fail cases) and is computationally light.
Implementing online RL
For RL-based post-training, this example uses the GRPO policy optimization algorithm. To do so, you can use the “GRPOTrainer” class from the Hugging Face TRL library.
import re
from trl import GRPOTrainer, GRPOConfig
Generating model response before RL
Import a news summarization dataset containing article text and highlights. Instruct an LLM to generate article summaries in less than 50 words. To evaluate model performance, count how many LLM-generated summaries are fewer than 50 words.
The script below imports the dataset.
model, tokenizer = get_model_and_tokenizer("Qwen/Qwen2.5-0.5B-Instruct")
rl_dataset = load_dataset("Oshadha-cse/news_summarization_dataset")["train"]
sample_dataset = rl_dataset.to_pandas().head(200)
print(f"Article: {sample_dataset['article'].iloc[0]}")
print(f"Summary:, {sample_dataset['highlights'].iloc[0]}")
sample_dataset.head(5)
Output:

The script defines helper functions to count words in a text input. The script also defines functions for generating summaries and evaluating model performance. In evaluation, you can assign a score of 1 if a summary is less than or equal to 50; else, assign a score of 0. This is an example of a verifiable reward.
Finally, evaluate the model’s performance on the first 10 articles in the dataset as shown below.
# tiny, robust word counter (drops angle-bracket tags, normalizes spaces)
_TAG_RE = re.compile(r"<[^>]+>")
_WS_RE = re.compile(r"\s+")
_WORD_RE = re.compile(r"\b\w+\b") # word-boundary based token finder
system_prompt: str = (
"Summarize the following news article in at most 50 words. "
"Make the summary concise and ensure it does not exceed the limit."
)
def count_words(text: str) -> int:
if text is None:
return 0
s = str(text)
s = _TAG_RE.sub(" ", s)
s = _WS_RE.sub(" ", s).strip()
return len(_WORD_RE.findall(s))
def generate_summary(model, tokenizer, article: str, sys_prompt: str) -> str:
# your existing single-turn helper
return generate_single_responses(
model,
tokenizer,
article,
system_prompt=sys_prompt
)
def evaluate_performance(
model,
tokenizer,
dataset: pd.DataFrame,
n: int = 50,
max_words: int = 50,
):
rows = dataset.head(min(n, len(dataset))).copy()
sys_prompt = system_prompt
records = []
for i, row in tqdm(rows.iterrows(), total=len(rows), desc="Evaluating"):
article = row["article"]
with torch.no_grad():
summary = generate_summary(model, tokenizer, article, sys_prompt)
wc = count_words(summary)
ok = int(wc <= max_words)
records.append({
"index": i,
"pred_word_count": wc,
"within_limit": ok,
"raw_summary": summary
})
df = pd.DataFrame(records)
compliance = df["within_limit"].mean() if len(df) else 0.0
print(f"\nLength compliance (first {len(df)} examples): {compliance:.2%}")
display(df)
return compliance, df
acc, df = evaluate_performance(model, tokenizer, sample_dataset, n = 10)
Output:
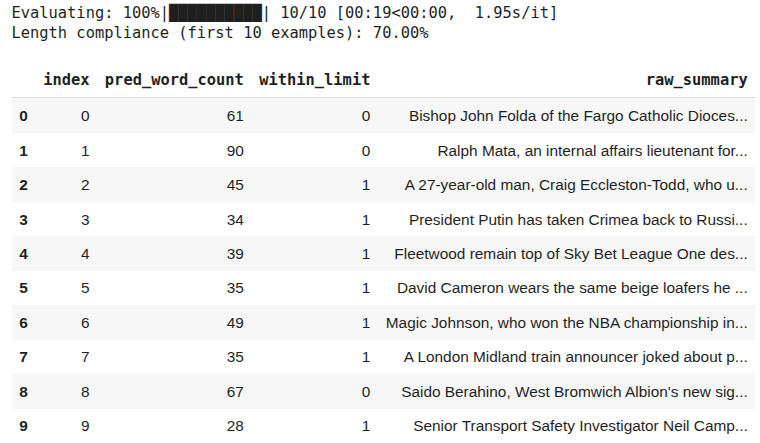
The output above shows that the model achieves 70% accuracy.
Perform RL and generate response
For RL, the first step is to define the reward function that guides an LLM to generate responses that maximize the reward.
The following script defines a helper function, “_to_text”, that extracts text from an LLM response. Next, you can define a reward function “reward_func” that calls the “_to_text” function to extract text from the LLM response. It returns a reward of 1 if the text's word count is 50 or fewer. If the word count goes over the limit, the reward gradually decreases depending on how far it goes past the limit.
def _to_text(batch_item):
if isinstance(batch_item, list):
if batch_item and isinstance(batch_item[0], dict):
return batch_item[0].get("content", "")
if batch_item and isinstance(batch_item[0], list):
return _to_text(batch_item[0])
if isinstance(batch_item, dict):
return batch_item.get("content", "")
return str(batch_item)
def reward_func(
completions,
ground_truth=None,
max_words: int = 50,
**kwargs
):
"""
- 1.0 if length ≤ max_words
- If over the limit, reward decays linearly with the overflow:
reward = max(0, 1 - (overflow / max_words))
This gives the model a gradient even when it's only slightly above the limit.
"""
rewards = []
for c in completions:
text = _to_text(c)
wc = count_words(text)
if wc <= max_words:
r = 1.0
else:
overflow = wc - max_words
r = max(0.0, 1.0 - (overflow / max_words))
rewards.append(r)
return rewards
You can test this reward function using the following script.
sample_pred = [
[{"role": "assistant", "content": "short concise summary with few words"}], # well under 50
[{"role": "assistant", "content": " ".join(["word"]*50)}], # exactly 50
[{"role": "assistant", "content": " ".join(["word"]*72)}], # over 50
]
print("Shaped:", reward_func(sample_pred, max_words=50))
Output:

The “GRPOTrainer” class expects data in the form of a nested dictionary. The key of the dictionary must be “prompt” and the value should be a list of internal dictionaries containing “system” and “user” response pairs.
The following script formats the dataset for “GRPOTrainer”
def format_for_grpo(sample_dataset, system_prompt):
prompts = [
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": row["article"]}
]
for _, row in sample_dataset.iterrows()
]
return Dataset.from_dict({"prompt": prompts})
formatted = format_for_grpo(
sample_dataset,
system_prompt=system_prompt
)
# preview first example
formatted[0]
Output:

Finally, you can start RL training using the final script. For details of the parameters, check the GRPOTrainer official documentation.
config = GRPOConfig(
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_generations=4,
num_train_epochs=1,
learning_rate=5e-6,
logging_steps=10,
report_to="none",
max_prompt_length=1536,
max_completion_length=1000,
)
grpo_trainer = GRPOTrainer(
model=model,
args=config,
reward_funcs=reward_func,
train_dataset=formatted
)
grpo_trainer.train()
Now, if you evaluate the RL post-trained model on the first 10 examples in the dataset, you should see the following response.
acc, df = evaluate_performance(grpo_trainer.model, tokenizer, sample_dataset, 10)
Output:
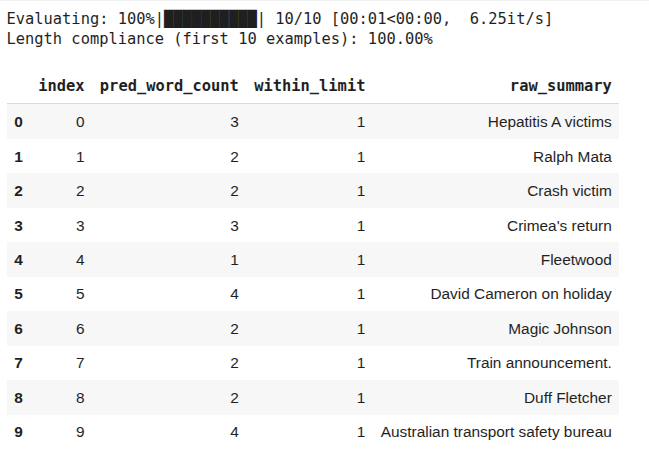
The above output shows that the RL post-trained model achieves 100% accuracy. However, you can also see that the generated responses are very short. This is a classic example of reward-hacking, where RL found an undesirable solution to achieve 100% accuracy. To overcome reward hacking, modify your reward function. Try a binary reward function instead of linear decay to see if you get better results.
Choosing between SFT, DPO and RL
The three LLM post-training approaches have their pros and cons. The choice of method depends on your requirements. In many real-world projects, these techniques are used in combination.
For example, you might use SFT to establish a base behavior, then apply DPO for fine-grained tweaks, and even an RLHF step to further optimize a particular metric. The key is to choose the minimal technique that achieves your goal. Don’t use RL if SFT solves the problem. However, don’t hesitate to use RL if you genuinely need that last mile of performance.
The following table presents a brief comparison of LLM-post training approaches.
With careful design of data and rewards, and rigorous evaluation, post-training allows you to transform a general LLM into a customized model for your specific application.
How Patronus AI helps
Patronus AI helps you train and evaluate AI agents with reinforcement learning environments that reflect real production needs. It is a platform built for analyzing and improving LLM and autonomous agents through detailed traces, clear feedback, and measurable rewards. You can see exactly where an agent performs well or fails, and use that insight to improve its behavior over time.
Unlike synthetic tests, Patronus offers RL environments based on real tasks such as coding, SQL query generation, customer support, finance question answering, and trading. Because these tasks reflect real use cases, improvements achieved here carry over directly to real systems.
Each environment provides automatic and verifiable reward signals. Instead of relying on manual judgment, Patronus checks correctness through tests, database validations, or schema checks. These signals are consistent and reproducible, which keeps the evaluation reliable and scalable.
Agents trained in one Patronus environment can also transfer what they learn to others. For example, a coding agent that learns to produce error-free, well-formatted code will apply the same discipline to new tasks. This consistency across domains helps reduce overfitting and encourages general reasoning skills.
Patronus supports many RL environment types, including:
- Coding and debugging agents
- SQL and database question answering
- Customer service and support flows
- Financial data insight generation
- Trading or simulated market interaction
- Web navigation and e-commerce task agents
Each comes with structured evaluation logic that checks correctness, order of operations, error handling, and consistency. With these tools, you can turn evaluation pipelines into full reinforcement learning environments and build agents that improve through measurable outcomes.
{{banner-dark-small-1-rle="/banners"}}
Final thoughts
LLM post-training transforms raw LLM capabilities into task-specific skills, resulting in customized model behavior. Different LLM post-training approaches have unique strengths. SFT gives broad behavior shifts with minimal effort, DPO allows precise corrections, and RL delivers measurable gains with verifiable outcomes. The right choice depends on your use case, available data, and level of control required.
Patronus AI makes this process easier by providing environments, feedback tools, and verifiable reward systems that connect evaluation with real improvement. It helps you understand why a model succeeds or fails and lets you turn that understanding into continuous progress.
Explore Patronus AI to see how post-training and reinforcement learning help you build models that are not only capable but also reliable and aligned with your real-world needs.

