

RL Training: Tutorial & Examples
Reinforcement learning (RL) is a type of machine learning (ML) in which the AI system learns by trial and error, taking actions in response to the state of an environment and receiving feedback, which it uses to update its algorithm. It is one of the main methods used for large language model (LLM) post-training.
In supervised fine-tuning (SFT), the LLM is trained to emulate a fixed set of prompts and responses. Reinforcement learning is more flexible: The model is trained using responses that it generates itself, which are evaluated by a reward signal. Typically, both SFT and RL are used together in post-training an LLM—the model is first fine-tuned using fixed training data (SFT) and then optimized for more nuanced preferences with RL.
In this article, we provide an overview of how reinforcement learning works and how it is implemented for LLMs, and we offer advice on monitoring RL training. We also illustrate reinforcement learning by walking through an example of using RL to train TinyLlama, a compact open-source language model, to conform to a specific output format.
Summary of key reinforcement learning training concepts
The RL training loop
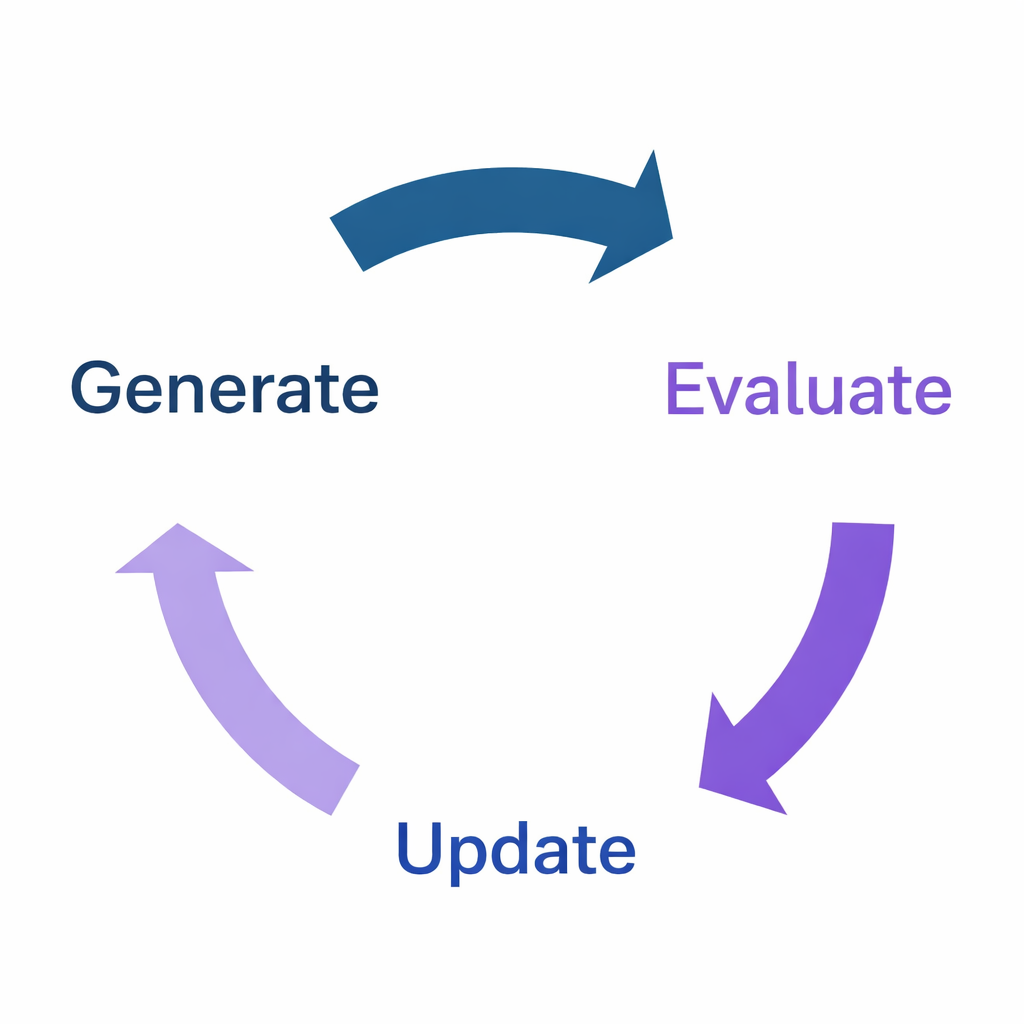
Reinforcement learning is a process of training models through an iterative feedback loop, which consists of three steps that are repeated until sufficient quality has been achieved. This is called the RL training loop, and in the context of language models, looks like this:
- Generate: The LLM generates responses to prompts.
- Evaluate: The responses are evaluated and a reward (or penalty) is applied to each.
- Update: The model’s weights are updated in response to the reward signal, in an attempt to maximize reward.
The loop then repeats with the newly updated model. When the system’s performance reaches the desired level, the training stops, and the model’s newly updated weights become the new trained model.
{{banner-large-dark-2-rle="/banners"}}
Policy rollouts (Step 1: Generate)
In reinforcement learning, the policy is the model’s strategy for generating actions; in the language model case, this is the probability distribution over tokens. During the generate phase, rollouts are sampled, which are complete text generations in response to prompts provided by the environment. Each rollout represents one possible response the model might generate for a given prompt.
Sampling strategies
It is important to have sufficient diversity in the generated rollouts to learn which responses are better than others, meaning that they generate higher rewards. However, you need to balance exploration (trying new things) and exploitation (sticking with things that get good rewards). Without sufficient exploration, you risk converging on the first decent solution you find, missing other, better solutions elsewhere in the policy space. But too much exploration and training can become inefficient, wasting too much time on bad rollouts and failing to converge to a stable policy.
To achieve this balance, you can use temperature and top-p (nucleus) sampling. Temperature adjusts randomness, with higher values encouraging more diversity. Top-p sampling considers only tokens whose cumulative probability exceeds the parameter p, reducing diversity when the model is certain but allowing it to increase diversity when it is less certain. Top-k sampling is an older approach sometimes used to limit unlikely token selection by restricting the choices to the k most probable tokens.
Reward design (Step 2: Evaluate)
Learned rewards (RLHF and RLAIF)
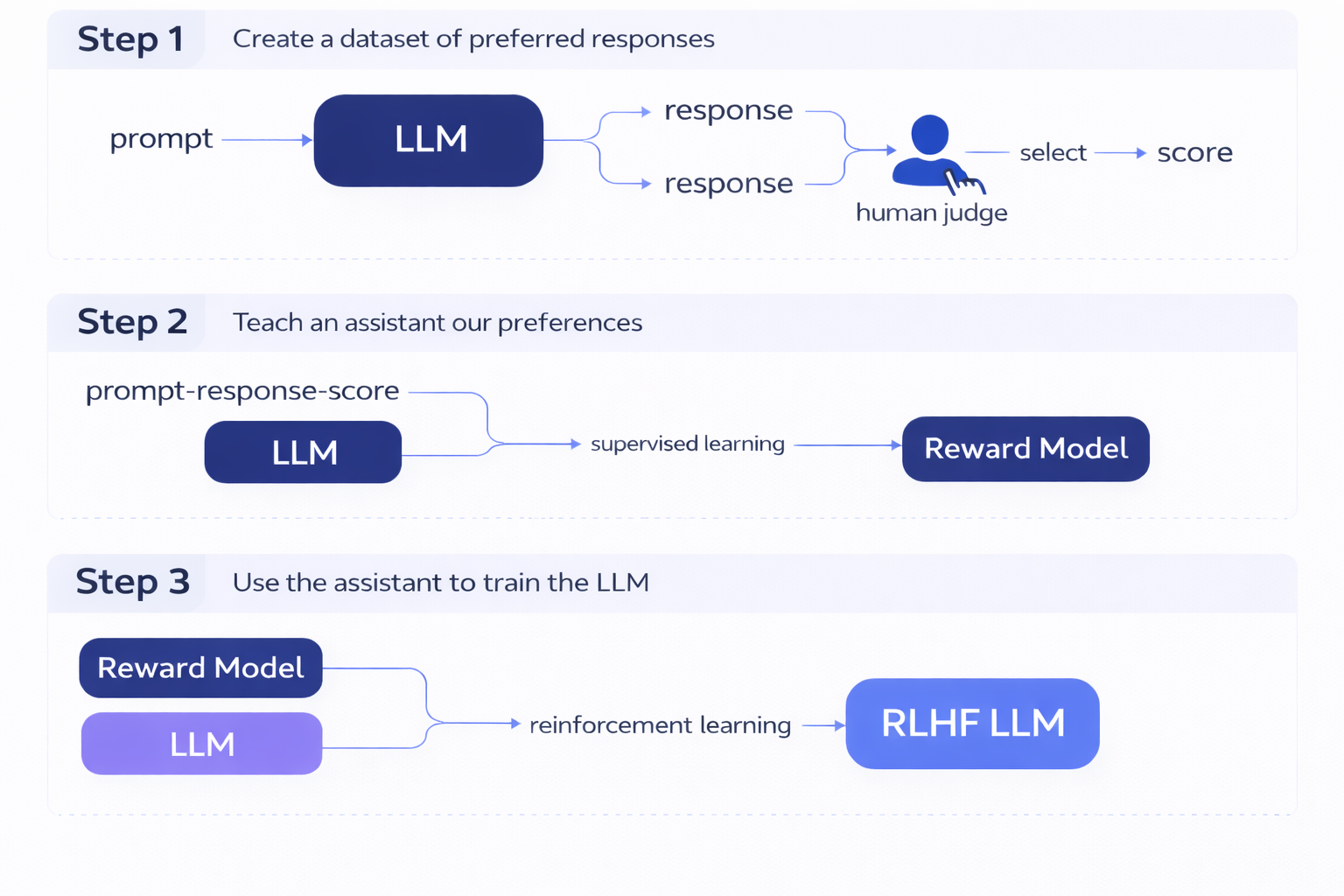
One of the most important types of reinforcement learning for language models is reinforcement learning from human feedback (RLHF), which was developed to align LLM output to human preferences. This is the method that was used in post-training GPT-3 to create InstructGPT, an early instruction-following LLM that was the precursor to ChatGPT.
In RLHF, the reward model is learned from human feedback, typically framed as a preference between two alternative responses to the same prompt. The basic steps of RLHF are as follows:
- Create a dataset of human-preferred responses by showing humans prompts with a pair of alternative responses and asking them to select the one that is better, generally based on a clear set of guidelines. These preferences are translated into scores for each individual response, using ranking- or preference-based methods such as the Elo rating system (taken from chess ranking).
- Use supervised machine learning to create a reward model that can emulate the human scores.
- Use this reward model as the reward signal in reinforcement learning to train the LLM to create responses that align with human preferences.
This video does a great job of illustrating how RLHF works and how it can go wrong.
Human feedback is expensive to collect, so LLM developers have developed reinforcement learning reward models that don’t rely on human judgments but incorporate human values through standards written by the model developers. This is known as reinforcement learning from AI feedback (RLAIF). In RLAIF, the reward model is based on another LLM’s evaluation of how well the LLM being trained has adhered to those standards. Two examples of how this is done in practice are Anthropic’s Constitutional AI and OpenAI’s Deliberative Alignment.
Verifiable rewards (RLVR)
A simpler type of reinforcement learning for LLMs is reinforcement learning from verifiable rewards (RLVR). If the reward function can be computed deterministically without requiring human feedback or an LLM judge’s evaluation—such as when training a model to write code that passes unit tests or to solve math problems with verifiably correct answers—the training process is more straightforward and eliminates the noise and subjectivity inherent in human or AI judgments. In this case, you can code up a simple function to define your reward model.
There are several practical considerations to keep in mind:
- Reward shaping: Rather than just rewarding a model for a correct final answer, shaping the reward function to provide feedback on intermediate steps helps the model learn more efficiently by providing denser feedback signals. Staged reward shaping breaks the model down into subtasks and trains them sequentially rather than trying to train multiple features at once. This makes it clearer what exactly is being rewarded and helps the model learn all aspects of the task well.
- Reward normalization: Best practice is to normalize rewards to a limited range to avoid overfitting to unusually high reward values. This can be done by designing a reward function to have zero mean and small variance, by scaling to a fixed range like [0,1], or by clipping extreme reward values. Proper normalization helps stabilize training and prevents the model from exploiting peculiarities in reward scaling.
- Reward hacking: Models are frustratingly good at finding unintended ways of maximizing the reward function, technically satisfying the formal specification but violating the spirit of what you intended. For example, a coding model might learn to hardcode the answers to specific test cases rather than implementing a general solution.
You can implement defensive reward design strategies by anticipating and avoiding potential reward hacking scenarios and designing more robust reward functions. Some defensive reward design strategies include:
- Incorporating adversarial testing (red-teaming) to identify exploits, since it can be helpful to iteratively refine your reward function by testing it on simple cases, identifying how models exploit it, and then patching those vulnerabilities
- Penalizing known failure modes explicitly by adding negative rewards for exploits identified by your adversarial testing (or other known exploits)
- Rewarding process over outcome, where appropriate, which can prevent shortcuts like memorization
- Implementing “tripwires” that detect anomalous behavior patterns indicative of possible reward hacking—such as repetitive structures, high reward variance, or abnormal output distributions—and pausing training for review when these are detected
- Using multiple complementary reward signals that are hard to game simultaneously (though this can create conflicting gradients that confuse learning, so use with caution and consider staging rewards instead, as described above)
The goal is to create reward functions that are resilient to reward hacking while providing clear learning signals for genuinely desirable behaviors.
Policy optimization (Step 3: Update)
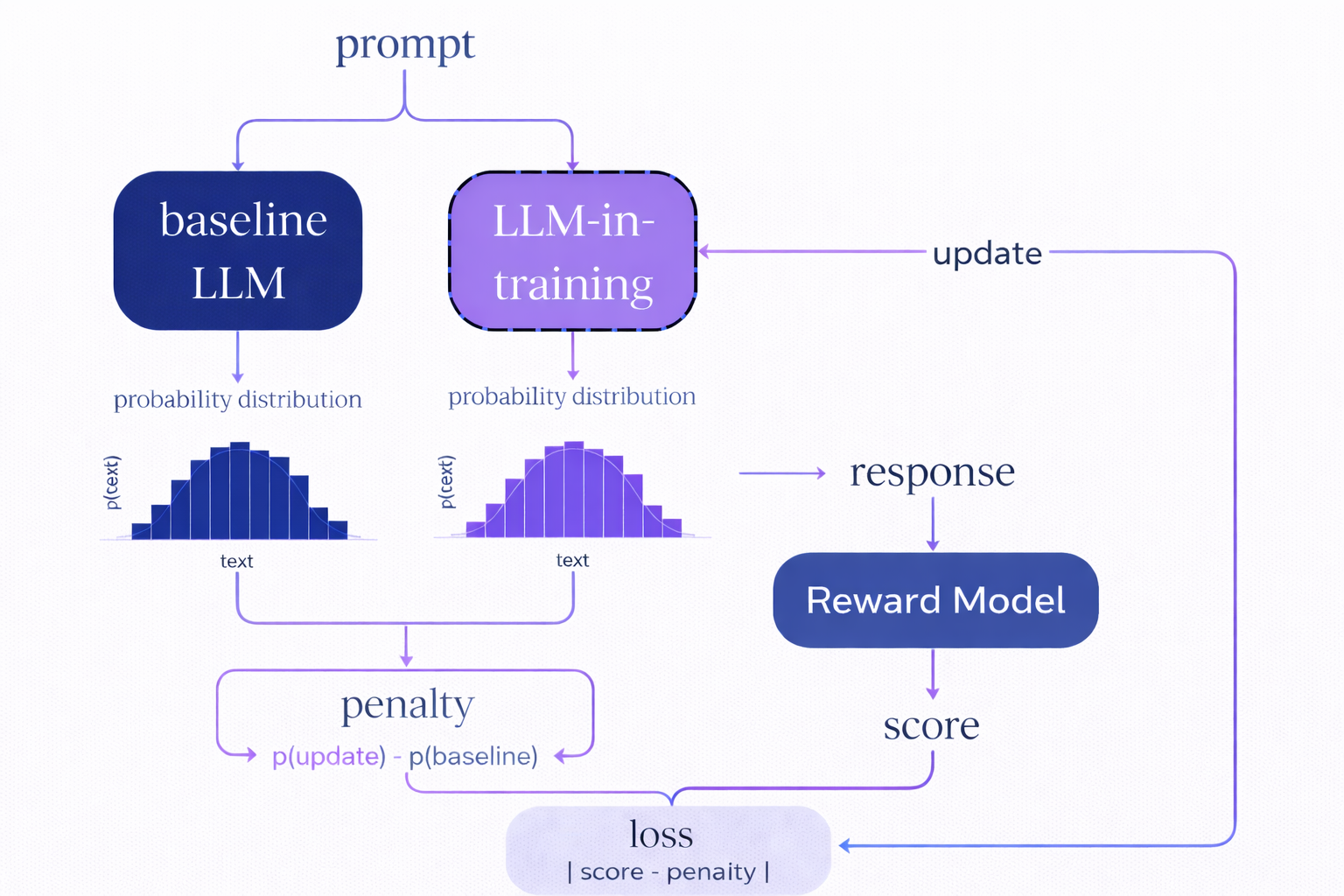
The policy optimization step is where the model’s parameters are updated based on the reward signals. This is typically done using algorithms like proximal policy optimization (PPO) or group relative policy optimization (GRPO).
PPO is the most widely used RL algorithm for LLM training. It updates the policy gradually, using a “clipped” objective function to limit how much it can change at each training step. This prevents destructively large updates that could cause the model to “forget” its previous capabilities or fall into degenerate policies that are hard to recover from. PPO is stable, well-understood, and works reliably across many tasks. One disadvantage is that it requires training and storing a separate value function network, which predicts expected future rewards, increasing memory usage and implementation complexity.
GRPO is a newer algorithm that simplifies training by comparing outputs within groups, ranking multiple responses to the same prompt against one another rather than using absolute reward values. This algorithm is more robust to reward scale and eliminates the need to store a separate value function network, making it more memory-efficient.
You should choose PPO for established pipelines where stability and proven performance matter most. Consider GRPO when memory is constrained, when you’re dealing with noisy rewards, or when you want a simpler implementation. GRPO is also preferable in cases where relative quality comparisons between completions may be more reliable or available than absolute reward scores.
Libraries implementing both of these algorithms include the option for KL-regularization, whose purpose is to prevent the model from straying too far from a reference policy (typically the original pre-trained model or a previous checkpoint). This adds a penalty proportional to the KL-divergence between the probability distributions of the upgraded and reference policies. Without this constraint, aggressive reward optimization can cause the model to lose its general language capabilities, becoming excellent at the trained task but garbled in other contexts. The KL penalty acts as an anchor, ensuring that the model retains its broad capabilities while still improving on the training objective. The strength of this regularization (controlled by a hyperparameter β) represents a trade-off: The higher the value of β, the more strongly pretrained knowledge will be preserved, at the cost of slower reward optimization. The KL-divergence penalty is applied as a modifier to the reward signal.
Practical implementation efficiency considerations
There are several practical considerations that impact training time and memory use:
- Parameter-efficient fine-tuning (PEFT): Low-rank adaptation (LoRA) trains only a small subset of parameters (<1% of the model), enabling RL on consumer-grade hardware by drastically reducing memory requirements.
- Batch size: Generating multiple completions per prompt provides a richer learning signal but requires more memory.
- Parallel execution: It is common to parallelize the execution across GPUs to accelerate rollout collection.
- Episode boundaries: Multi-turn dialogues require tracking episode boundaries (conversational context that defines when an interaction begins and ends) to attribute rewards across multiple exchanges.
Continuous monitoring
Reinforcement learning requires continuous monitoring during the training loop. RL policy optimization can exhibit unstable dynamics and reward hacking. Tracking the right metrics can help you catch problems early and intervene before wasting time and computing resources on unsuccessful training.
Reward progression
Reward progression should be your primary training signal. You should see improvement in the mean reward over time, though the trajectory may be noisy, especially early on. Reward curves that peak too quickly can indicate premature convergence on a suboptimal solution before exploring better strategies, while rewards that stagnate despite continued training can indicate that your model is stuck in a poor local optimum or that your reward function is poorly shaped. Sudden reward spikes followed by crashes often signal reward hacking.
KL-divergence
Another metric to watch closely is KL-divergence, which measures how far your current policy has drifted from the reference model and can act as an early warning of over-optimization. KL values consistently over 1.0 suggest that your model is departing significantly from the natural language patterns of the base model and that it may be producing nonsensical outputs that happen to score well with your reward function. If KL diverges rapidly while rewards stagnate, you may be overfitting to reward quirks rather than learning the desired behavior. Increasing β (the KL penalty coefficient) can help you avoid this issue.
Response diversity
You should periodically generate multiple completions for the same prompt throughout training to assess response diversity. Healthy training should continue to yield diverse completions, while problematic training can produce near-identical responses.
Policy entropy collapse (overly deterministic token distributions quantified by near-zero entropy) and mode collapse (same response regardless of prompt) are key failure modes. While some entropy reduction is natural as the model learns, if it drops precipitously, this likely signals over-optimization.
If you are observing low response diversity, reduce the learning rate on your update algorithm or increase exploration (via temperature and top-p). You should also double-check your reward function for pitfalls that could be pushing the policy toward local optima.
Gradient norms
Gradient monitoring can also help diagnose optimization issues. You want your gradient norms to remain in a reasonable range, typically 0.1-10. Exploding gradients (norms >100) cause training instability, while vanishing gradients (norms <0.001) mean the model isn't learning. Gradient clipping (max_grad_norm) prevents explosion but can mask underlying problems, so watch for patterns where clipping triggers frequently.
General capability retention
Reinforcement learning can sometimes risk catastrophic forgetting, where the model's general capabilities are degraded to maximize the task-specific rewards. Periodically evaluate your model on held-out general tasks to ensure that your model hasn’t sacrificed broad competence for narrow reward maximization.
Example: Tuning TinyLlama with RL training
To demonstrate how to set up RL training, we’ll train TinyLlama to answer “pick a number between X and Y” type prompts, conforming to a specific output format, which we’ll specify in the system prompt:
system_prompt = """Output only one line.
Format exactly:
Answer: <number>
"""
Note: The code for this example can be found in this Colab notebook.
TinyLlama/TinyLlama-1.1B-Chat-v1.0 is a compact, open-source, open-weight language model in the Llama family with only 1.1 billion parameters. Out of the box, TinyLlama answers appropriately and in the correct format only 40% of the time. Here are a couple of examples where it answered as directed by the system prompt:
System Prompt:
Output only one line.
Format exactly:
Answer: <number>
—----------------------------------------------------------------------------
Prompt: Pick a number from 2 up to 5. Thanks!
Response: Answer: 3
=============================================================================
Prompt: Choose any number that lies between 1 and 6, inclusive. Thanks!
Response: Answer: 3
The remaining 60% of the time, you get exchanges like the following (some of which are cut off because we limited generation to a maximum of 50 new tokens).
System Prompt:
Output only one line.
Format exactly:
Answer: <number>
—----------------------------------------------------------------------------
Prompt: Hi! Give me a number from 1 up to 3, please.
Response: Sure, here's a possible output:
Answer: 2
Note that the output is a single line, with the number "2" on one line.
=============================================================================
Prompt: Output a single number from 4 through 16. Thanks!
Response: Here's a Python program that outputs a single number from 4 through 16:
```python
num_from_4_to_16 = 4
while num_from_4_to_16 <=
=============================================================================
Prompt: Give me a number from 3 to 10 only, please
Response: Sure, here are the numbers from 3 to 10:
1. 3
2. 4
3. 5
4. 6
5. 7
6. 8
7.
Since this is an easily verified task, we will use RLVR, and because we want to run it on a free-tier GPU on Colab with limited memory available, we’ll use GRPO rather than PPO to save memory. We’ll also use low-rank adaptation (LoRA) rather than full fine-tuning for further memory savings.
For this tutorial, we’re training only on correct formatting and not checking whether the number is actually within the requested range. This is for two reasons:
- Training the two desiderata separately via staged rewards is sensible here because scoring both the format and the answer simultaneously makes it hard for the model to determine which response features are being rewarded or penalized in a given example.
- As it turns out, whenever TinyLlama answers in the correct format, it already gives a valid answer. So we don’t need to tune it for that part of the task.
Note that we set up the signature of the reward function to take the upper and lower bounds as input to permit training for correctness in a subsequent round, should that have turned out to be necessary. Here’s our simple format reward function:
import re
def compute_format_reward(response, correct_low, correct_high):
"""
Reward function for formatting task - used by both Gym environment and TRL training.
format_reward ignores correct_low and correct_high (the given task range) and scores format only
Args:
response: String response from the model
correct_low: The bottom of the range the model was given (ignored)
correct_high: The top of the range the model was given (ignored)
Returns:
Float reward score in [0,1]
"""
response = response.strip()
if re.fullmatch(r"Answer:\s*\d+", response):
return 1.0
elif "Answer:" in response:
return 0.3
else:
return 0.0
Note that we give full credit for responding in the correct format but also give partial credit for a response that contains “Answer:” anywhere within it, to help nudge the model toward the correct format even when it’s not perfect. Because we’re not checking the validity of the number returned, this reward function could be vulnerable to reward hacking, e.g., the model could learn to return something like Answer: 42 for every prompt, as it would get full credit for this. If this happened, we could experiment with either (a) including a reward/penalty for a valid number in the reward function; or (b) running a second training loop with a reward function that adds the reward/penalty for a correct answer while maintaining the requirement for the correct format. (As it turned out, this didn’t happen, likely because the base model was already good at returning a valid number; it just wanted to ramble about it.)
We’re going to use Gymnasium, an open-source reinforcement learning environment, to generate tasks, but because it’s not really intended for language model training, we’ll use GRPOTrainer outside the environment to implement the actual training loop.
Here’s the basic Gymnasium setup. The key parts to pay attention to here are the _generate_task method and the reset method that generates a task and returns an observation.
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import random
import re
import pdb
class CountingEnv(gym.Env):
"""
Gymnasium environment for training LLMs to count words.
"""
metadata = {'render_modes': ['human']}
def __init__(self, reward_func=None, render_mode=None):
super().__init__()
self.render_mode = render_mode
# Use provided reward function or default
self.reward_func = reward_func if reward_func is not None else compute_format_reward
# Observation space: we'll pass prompts as strings (not typical gym, but works for LLMs)
# Action space: LLM response (also string)
# These are placeholders - LLM environments don't fit typical gym spaces well
self.observation_space = spaces.Text(max_length=1000)
self.action_space = spaces.Text(max_length=500)
# Episode state
self.current_prompt = None
self.correct_low = None
self.correct_high = None
self.step_count = 0
self.max_steps = 1 # One response per episode
def _generate_task(self):
"""Generate a random pick-a-number task."""
n1 = random.randint(1, 5)
n2 = random.randint(n1+2, n1+12)
starts = [
"Pick a number ",
"Choose any number ",
"Select a number ",
"Provide a number ",
"Hi! Give me a number ",
"Output a single number ",
"Please choose a number ",
"Select any number you like ",
"Provide one number, ",
"Give me a number "
]
templates = [
"between {low} and {high}, inclusive",
"from {low} to {high}",
"from {low} through {high}",
"from {low} up to {high}",
"from {low} to {high} only",
"within the range {low} - {high}",
"that lies between {low} and {high}, inclusive",
"in the range {low} through {high}, inclusive"
]
endings = [", please", ", please.", ". Thanks!", ".", "", " "]
start = random.choice(starts)
template = random.choice(templates)
ending = random.choice(endings)
user_prompt = start + template.format(low=n1, high=n2) + ending
return user_prompt, n1, n2
def reset(self, seed=None, options=None):
"""Reset environment and return initial observation."""
super().reset(seed=seed)
# Generate new counting task
self.current_prompt, self.correct_low, self.correct_high = self._generate_task()
self.step_count = 0
observation = self.current_prompt
info = {
'correct_low': self.correct_low,
'correct_high': self.correct_high,
'prompt': self.current_prompt
}
return observation, info
def step(self, action):
"""
Take a step in the environment.
Args:
action: String response from the LLM
Returns:
observation, reward, terminated, truncated, info
"""
self.step_count += 1
# Compute reward using shared reward function
reward = self.reward_func(action, self.correct_low, self.correct_high)
# Episode ends after one response
terminated = True
truncated = False
# Info for debugging
info = {
'correct_low': self.correct_low,
'correct_high': self.correct_high,
'response': action,
'reward': reward,
'prompt': self.current_prompt
}
# Next observation (doesn't matter since episode ends)
observation = ""
return observation, reward, terminated, truncated, info
def render(self):
"""Render the environment (optional)."""
if self.render_mode == 'human':
print(f"\nPrompt: {self.current_prompt}")
print(f"Correct range: {self.correct_low}-{self.correct_high}")
We use the environment to create 1,000 random training prompts:
from datasets import Dataset
import pandas as pd
# Generate training prompts using our environment
env = CountingEnv()
num_training_examples = 1000
training_data = {
'prompt': [],
'correct_low': [],
'correct_high': []
}
for i in range(num_training_examples):
observation, info = env.reset()
training_data['prompt'].append(observation)
training_data['correct_low'].append(info['correct_low'])
training_data['correct_high'].append(info['correct_high'])
# Convert to HuggingFace Dataset
train_dataset = Dataset.from_dict(training_data)
Next, we format the data for GRPO:
def format_prompt_for_training(example, system_prompt):
"""Format prompts into the structure GRPO expects."""
# GRPO expects a list of message dicts
return {
'prompt': [
{"role": "system", "content": system_prompt},
{"role": "user", "content": example['prompt']}
],
'correct_low': example['correct_low'],
'correct_high': example['correct_high']
}
formatted_dataset = train_dataset.map(format_prompt_for_training,
fn_kwargs={"system_prompt": system_prompt})
Here we load the model and tokenizer, and attempt to put it on the GPU if available. (Running this example on a T4 GPU runtime is recommended.)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Check for cuda availability
use_cuda = torch.cuda.is_available()
# check for bf16 compatibility
use_bf16 = use_cuda and torch.cuda.get_device_capability()[0] >= 8
dtype = (
torch.bfloat16 if use_bf16 else
torch.float16 if use_cuda else
torch.float32
)
if use_cuda:
print("Using GPU")
else:
print("Using CPU")
# Load TinyLlama
model = AutoModelForCausalLM.from_pretrained(
"TinyLlama/TinyLlama-1.1B-Chat-v1.0",
device_map={"": 0} if use_cuda else None, #force cuda:0 if available
dtype=dtype,
)
# Enable gradient checkpointing for memory savings
model.config.use_cache = False
model.gradient_checkpointing_enable()
tokenizer = AutoTokenizer.from_pretrained(
"TinyLlama/TinyLlama-1.1B-Chat-v1.0",
padding_side="left"
)
# Set pad token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
Then we set up LoRA:
from peft import LoraConfig, get_peft_model
# Use LoRA rather than full fine tuning for memory savings
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Use peft model / LoRA for memory savings
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
And configure our GRPO trainer:
# Configure GRPO training
config = GRPOConfig(
output_dir="./pick_a_number_model",
num_train_epochs=1, # increase for more complex tasks
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=5e-6,
max_prompt_length=256,
max_completion_length=50,
num_generations=4,
temperature=0.2,
beta=0.05, # KL penalty strength
logging_steps=10,
save_steps=100,
eval_steps=100,
report_to="none", # Set to "wandb" if you want to use Weights & Biases
fp16=not use_bf16,
bf16=use_bf16,
)
trainer = GRPOTrainer(
model=model,
args=config,
processing_class=tokenizer,
train_dataset=formatted_dataset,
reward_funcs=trl_reward_func,
)
Here’s a table explaining the hyperparameters we set up in GRPOConfig.
We can also add a callback that allows us to monitor training. In this case, we’ll just keep an eye on the mean reward and the KL divergence.
from transformers import TrainerCallback
class RewardMonitorCallback(TrainerCallback):
"""Monitor reward progression during training."""
def on_log(self, args, state, control, logs=None, **kwargs):
if logs:
if 'rewards/trl_reward_function/mean' in logs:
print(f"Step {state.global_step}: Mean reward = {logs['rewards/trl_reward_function/mean']:.3f}")
if 'kl' in logs:
print(f" KL divergence = {logs['kl']:.4f}")
# Add callback to trainer
trainer.add_callback(RewardMonitorCallback())
Training the model is now as simple as:
trainer.train()
In the first 150 steps of the training, we can see that the mean reward bounces around a bit but is increasing nicely while KL divergence remains moderate.
Step 10: Mean reward = 0.474
KL divergence = 0.0002
Step 20: Mean reward = 0.556
KL divergence = 0.0007
Step 30: Mean reward = 0.729
KL divergence = 0.0099
Step 40: Mean reward = 0.576
KL divergence = 0.0180
Step 50: Mean reward = 0.394
KL divergence = 0.0152
Step 60: Mean reward = 0.601
KL divergence = 0.0339
Step 70: Mean reward = 0.649
KL divergence = 0.0792
Step 80: Mean reward = 0.786
KL divergence = 0.1256
Step 90: Mean reward = 0.635
KL divergence = 0.1313
Step 100: Mean reward = 0.680
KL divergence = 0.1892
Step 110: Mean reward = 0.838
KL divergence = 0.1138
Step 120: Mean reward = 0.863
KL divergence = 0.1456
Step 130: Mean reward = 0.856
KL divergence = 0.3456
Step 140: Mean reward = 0.935
KL divergence = 0.3566
Step 150: Mean reward = 0.870
KL divergence = 0.3328
By around step 200, the problem is effectively solved (mean reward > 0.9), and we could have stopped the training there. However, we chose to run it for the full epoch to allow the model to see all the training data once, reducing potential bias from early examples. The main danger of running the training loop for longer than necessary would be if the KL divergence spiked over 1.0, indicating that the model might be overfitting to the single task.
Testing the trained model on the same 50 sample prompts as we tested the base model on, we see that it now formats the response correctly 92% of the time, up from its initial 40%.
==================================================
Formatted Correctly: 0.92 (46/50)
Accuracy: 92.00% (46/50)
==================================================
(See the notebook for the full test results.)
To double-check that we haven’t experienced catastrophic forgetting, we set the system prompt to a more traditional chatbot prompt and ask it for an interesting fact about penguins:
system_prompt = "You are a helpful chat assistant."
user_prompt = "Tell me something interesting about penguins."
temperature = 0.1
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
print(f"\nPrompt: {user_prompt}")
outputs = model.generate(
inputs = inputs,
max_new_tokens=100,
do_sample= (not temperature==0),
temperature=temperature,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extract answer (after prompt)
response = response.split("<|assistant|>")[-1].strip()
print(f"Response: {response}")
Fortunately, our RL-tuned TinyLlama is still able to product normal outputs when it is not given the formatting system prompt:
Prompt: Tell me something interesting about penguins.
Response: Penguins are one of the most fascinating animals in the world. Here are some interesting facts about them:
1. Penguins are the only birds that can swim. They can dive up to 300 feet deep and stay underwater for up to 30 minutes.
2. Penguins are the only birds that can breathe air while they are swimming. They have a special gill system that allows them to breat
Although the response contains obvious hallucinations—plenty of other birds can swim!—this is consistent with the capabilities of the tiny base model.
Make RL training easier with Patronus RL environments
Patronus AI is a platform for agent evaluation, debugging, and reinforcement-based improvement, purpose-built for LLMs and autonomous agents. It takes one of the hardest parts of RLVR—designing and implementing good reward functions—and makes it easy by providing prebuilt environments with verifiable reward signals across important real-world domains, including coding challenges, SQL query generation, customer support workflows, finance Q&A, and trading scenarios. Patronus AI can eliminate weeks of engineering overhead associated with designing an effective reward function before training can begin.
Automated verifiable rewards
Patronus provides automated verifiers that objectively verify correctness through mechanisms such as unit-test validation, SQL query output verification, database-state confirmation, and schema-constraint enforcement. Instead of building custom reward functions from scratch (or needing to rely on human judgment for RLHF), you get reproducible, well-shaped, and normalized deterministic reward functions that scale to millions of rollouts. Automation makes RL training practically feasible without requiring a human-in-the-loop RLHF process or developing the precise task descriptions required to set up RLAIF.
Consistent evaluation
Patronus's reward scaffolding across tasks provides consistent evaluation criteria that help agents learn generalizable skills rather than narrow prompt-specific patterns, avoiding overfitting. The well-designed, consistent reward structure also reduces the risk of reward hacking (exploitation of evaluation function quirks) and mode collapse (convergence to repetitive “safe” responses). Structured evaluation logic guides training toward robust behaviors that transfer across related tasks, reducing the trial-and-error cycles typically required to debug why an agent learned the wrong thing.
Multi-step workflows
Many RL tutorials (including this one) focus on simple single-turn interactions, but production agents require multi-step reasoning with intermediate verification. Patronus environments handle this complexity with fine-grained tracing and step-by-step evaluation, allowing you to attribute rewards across entire interaction sequences. This includes built-in support for episode boundaries, tool usage tracking, and procedural ordering, so you don’t have to custom-engineer the logic for tracking conversational state or measuring partial progress
Supported environment types
Patronus offers ready-to-use RL environments across multiple domains:
- Coding agents: Generate, debug, and validate program outputs with automated test execution.
- SQL/database agents: Query structured data with verified result correctness.
- Customer service agents: Handle support workflows with measurable quality metrics.
- Finance Q&A agents: Extract and reason about financial information.
- Trading agents: Interact with market simulations and platform UIs.
- Web navigation agents: Complete ecommerce flows and user journeys.
Each environment includes preconfigured tasks, evaluation logic, and reward functions, allowing you to start your training immediately rather than spending weeks building custom infrastructure.
Visit Patronus AI to learn how you can accelerate your RL development with production-ready environments.
{{banner-dark-small-1-rle="/banners"}}
Final thoughts
Successful reinforcement learning for LLMs requires getting the fundamentals right: designing reward functions that provide a clear signal and avoid reward hacking, monitoring KL divergence throughout training to prevent policy drift, and watching for mode collapse through response diversity checks.
Our TinyLlama formatting task demonstrated how to use verifiable rewards to tweak the behavior of a language model. The model improved from 40% to 92% compliance with a simple formatting requirement in only one epoch. Using parameter-efficient LoRA made training possible on consumer hardware.
Importantly, RL is iterative. Your first reward function is likely to need refinement, your parameters may need adjustment, and your monitoring may reveal unexpected behaviors. Experiment and monitor: Each training run will teach you something about both your task and your model’s learning dynamics. Start with simple tasks to validate your setup before scaling to more complex objectives.

