

Online Reinforcement Learning: Tutorial & Examples
Large language models (LLMs) are trained on enormous amounts of general data. Customizing the LLMs for application-specific tasks requires post-training using techniques such as supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning (RL).
There are two primary types of reinforcement learning for LLM applications: online and offline. The main distinction between the two lies in their mechanisms for collecting feedback. Offline reinforcement learning relies on previously collected datasets for feedback. It is fundamentally constrained by static datasets and fixed reward models, limiting its adaptability to evolving tasks and real-world usage.
In contrast, online reinforcement learning takes in real-time feedback from the environment. It learns from live interactions, user feedback, and dynamically evolving contexts, typically collecting experience continuously while periodically updating policies.
Online reinforcement learning enables continual performance improvement beyond initial pretraining and offline fine-tuning. It improves error correction and handles policy distribution shifts more effectively.
This article covers all aspects of online reinforcement learning for LLM alignment, including reward function design through end-to-end code examples. It also introduces useful tools to simplify LLM alignment or post-training tasks.
Summary of key concepts in online RL for LLMs
How does reinforcement for LLMs work?
Reinforcement learning establishes an agent-and-environment interaction-based learning mechanism that is optimized through the reward function. The figure below illustrates a general-purpose classical RL mechanism.
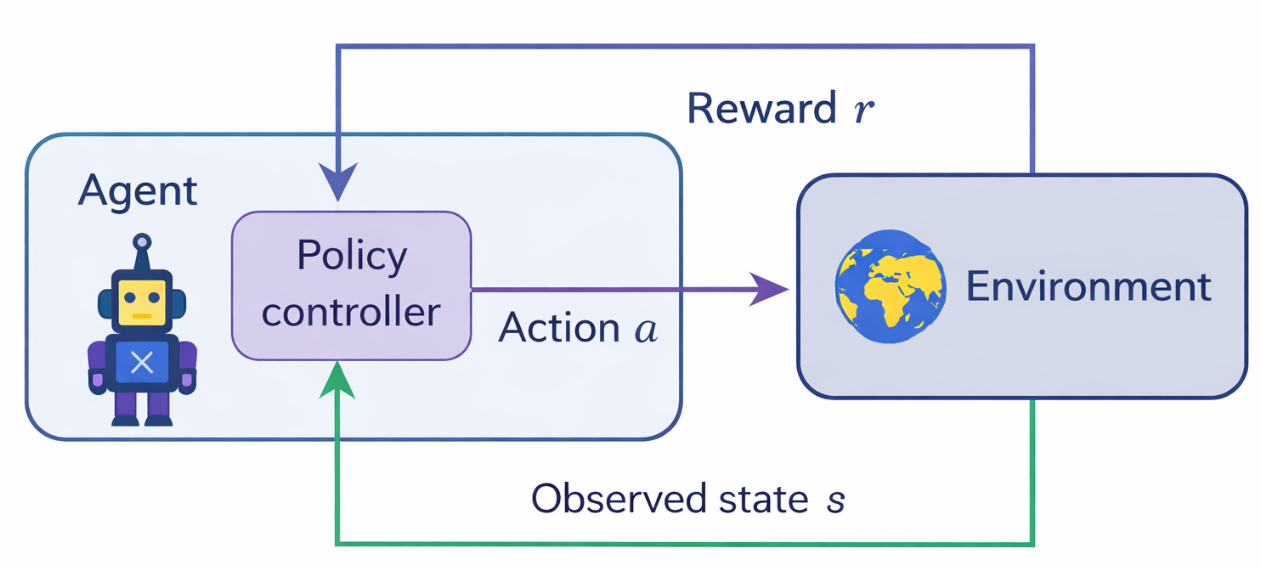
In online reinforcement learning for LLMs, the observable state can include:
- User input text
- Conversation history (previous turns)
- System instructions
- Tool outputs
- External context and metadata.
This state representation is partially observable because the model cannot access hidden user intent or external context directly. The LLM generates a response that replicates the action taken in classical RL. However, in online RL, the action is a sequence of tokens drawn from a high-dimensional action space.
The LLM's generated response is passed through a feedback mechanism; note that modelling the feedback for a high-dimensional action is exponentially more challenging than classical RL.
{{banner-large-dark-2-rle="/banners"}}
Understanding the reward model in reinforcement learning
A reward model or programmatic verifiers quantify how desirable a model’s output or action is as a reward signal. They estimate the reward signal from human feedback, automated verifiers, or learnt reward models for large text outputs. The reward signal specifically targets optimization objectives such as cost, scalability, and quality alignment.
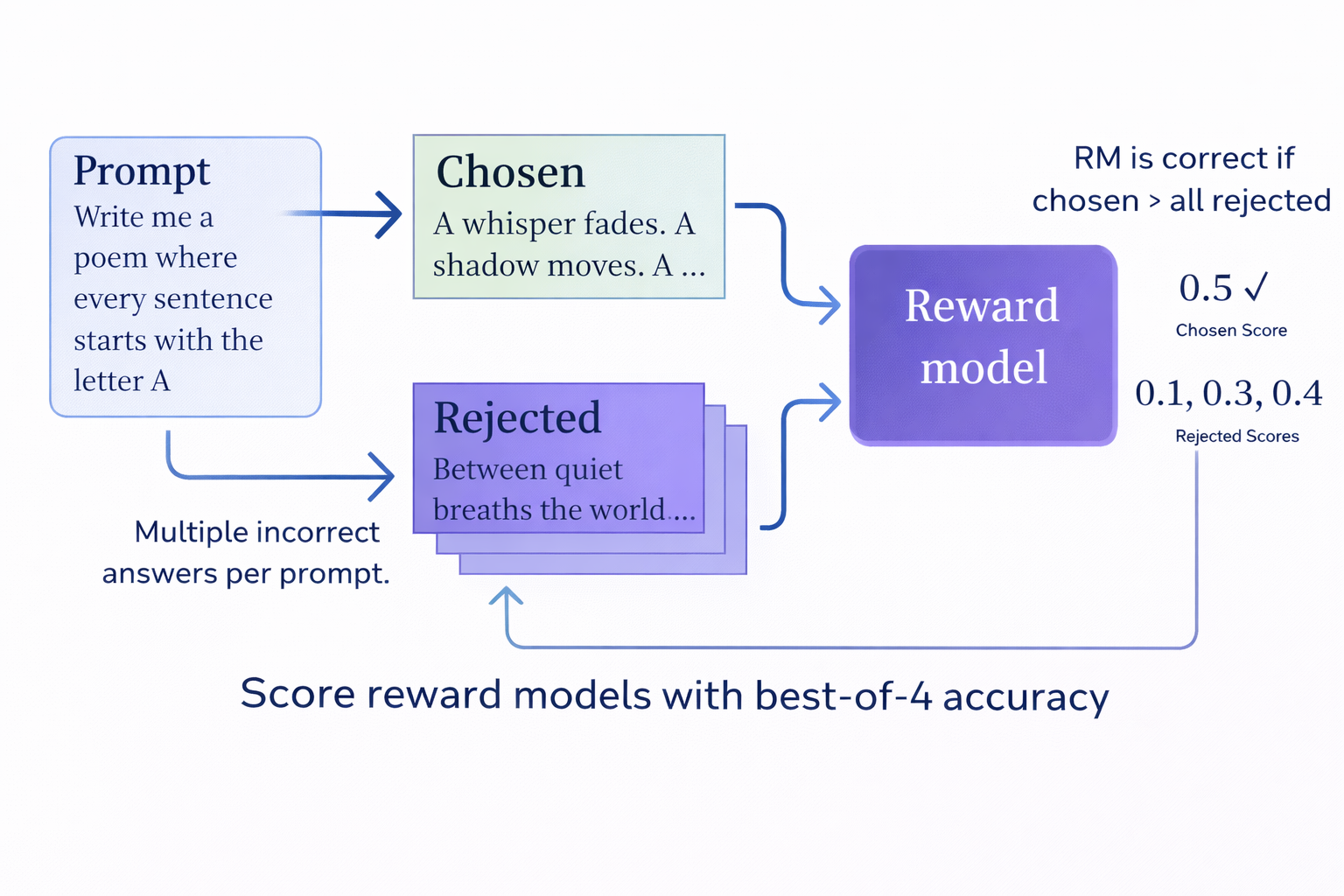
Let’s take an example prompt to understand the reward model. A user wants a poem written in a certain way. The reinforcement learning framework generates multiple candidate responses and scores them by comparing each LLM output against the user's requirements.
The score becomes the reward signal and is passed to the policy optimization algorithm (e.g., PPO), which updates the model’s parameters to increase the likelihood of producing high-reward outputs in future generations. This mechanism is summarized in the image below.
Types of reward models
In practice, reward signals for LLMs are often composed of multiple automated or learnt signals. Depending on the supervision source, reward models may be trained using:
- Human preference data (RLHF-style)
- Objective, verifiable signals (RLVR-style), or
The primary distinction between them is the source of feedback.
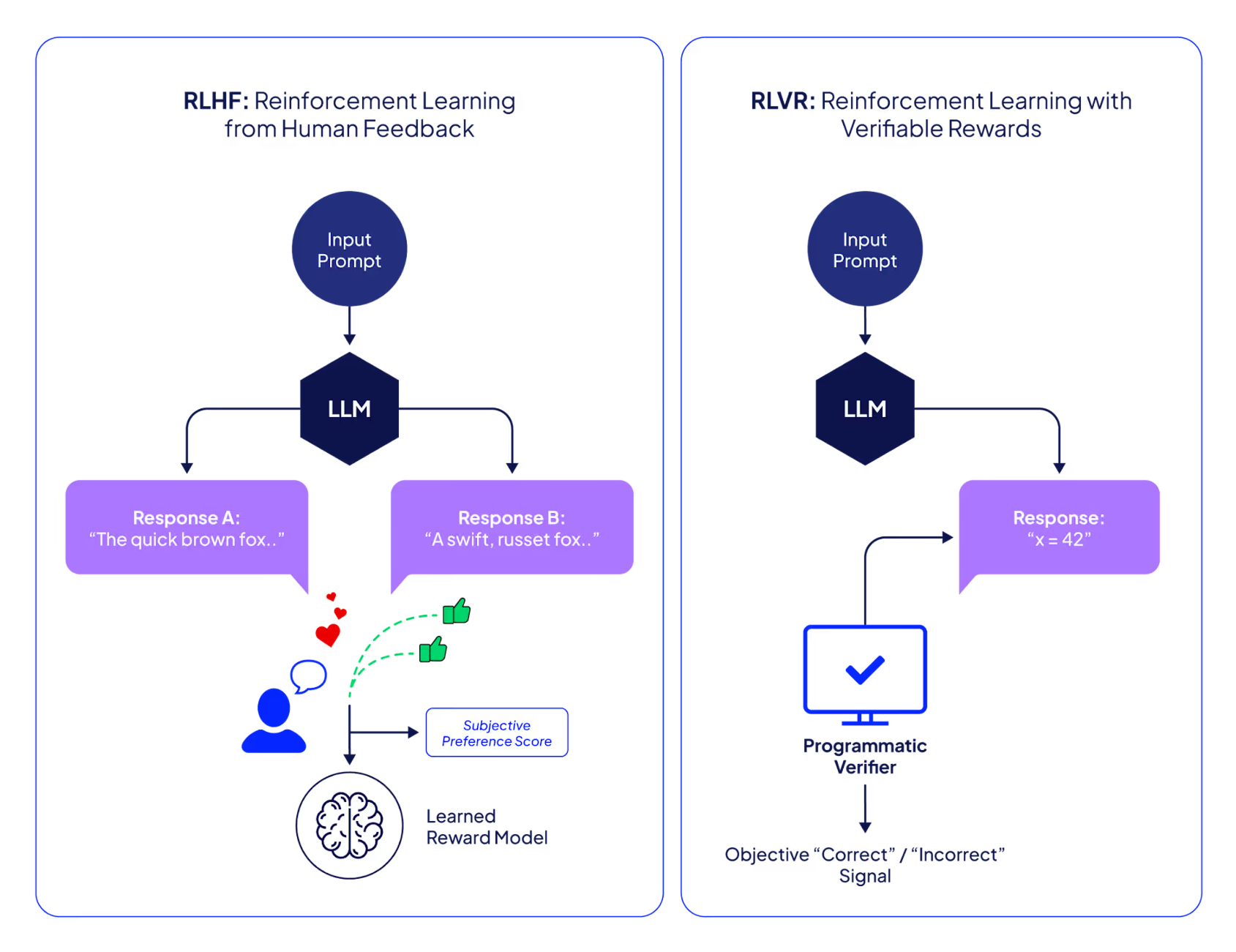
Reinforcement learning from human feedback (RLHF)
Domain experts or user feedback guide the process. Usually, a human user chooses the preferred response from two or more responses to a single prompt. Values and preferences are captured through human interactions rather than explicit algebraic rewards.
Pros
Open-ended linguistic tasks, dialogue systems, and situations in which subjective quality outweighs objective accuracy necessitate RLHF. Human input addresses complicated preferences for utility, coherence, style, decorum, and safety, whereas formal verifiers cannot. It can also be used in the absence of a trustworthy automatic reward function.
Human oversight enables models to adapt to changing cultural standards and user expectations, particularly in interactive systems serving diverse user populations.
Cons
The primary RLHF constraints are cost, time delay, and scalability. High-quality human feedback is costly and time-consuming, making regular online modifications unfeasible.
There is also a chance that unregulated human judgments can lead to instability, inconsistency, and bias in online learning. Hence, RLHF is rarely used as the sole signal in fully online settings and is more often applied selectively, periodically, or in combination with other automated rewards.
Reinforcement learning with verifiable rewards (RLVR)
RLVR implements an automatic correctness verification process. The reward signal is objectively measured through a suite of tests or verifier models, omitting the human from the training loop.
However, these verification mechanisms are typically designed with input from domain-specific subject matter experts (SMEs), ensuring that the reward signals reflect real-world standards and professional practices. Unlike RLHF, where humans directly evaluate and rank model outputs during training, RLVR incorporates human expertise earlier in the process by defining the verification rules that automatically assess the correctness of model outputs.
RLVR is primarily used for fine-tuning reasoning-focused LLMs. Correctness verification processes can be probabilistic or deterministic, symbolic or learnt, and heuristic or approximate.
Pros
RLVR excels at objective, programmed reward areas. Deterministic assessments, such as unit tests, compilers, formal verification tools, and constraint solvers, result in low variability, high reproducibility, and cost-effective computing. Because regulations are adjusted in real time, prompt feedback cycles are useful in online reinforcement learning.
The verifier's marginal cost is almost constant and can be parallelized over large sample sizes, making RLVR scalable.
RLVR is suited for high-throughput applications and rapid policy changes without human interaction. It maintains monitoring and reduces preference drift via objective rewards.
Cons and solution
The use of RLVR is limited to situations where the feedback's correctness can be reliably proven, as it is intrinsically inapplicable when no verifiable or auditable reward signal is defined.
Models, heuristics, and rule-based systems may have biases, weak specifications, and elements that are disregarded rather than objective reality. When models are trained primarily against verifiers that exploit reward logic flaws, reward hacking or narrow-criteria optimization might also occur.
RLVR prioritizes precision and constraint compliance over usefulness, tone, logical clarity, and user delight. Verification signals rarely indicate safety unless specifically built for it.
As a result, RLVR-based online reinforcement learning pipelines require KL regularization in comparison to a reference policy, conservative update schedules, reward audits, and explicit safety filters to prevent undesirable behavior.
RLVR vs. RLHF
Online reinforcement learning for large language models employs RLHF and RLVR to achieve complementary but distinct objectives. The method you choose depends on the task structure, the reward signal's dependability, and practical constraints such as annotation costs, system latency, and scalability.
Both strategies are employed in practical online reinforcement learning for large-scale language models. When objective verification is supplied, RLVR enables scalable, low-latency policy changes, whereas RLHF directs subjective alignment, safety, and user-centric quality.
Common RLVR applications include code generation via compilation or test suites, SQL query validation, mathematical problem solving using known solutions, logical consistency verification, API usage validation, and schema or syntax enforcement. RLVR is a trustworthy indicator of incremental improvement throughout a planned online deployment.
Popular RL methods
Proximal Policy Optimization (PPO) is an on-policy method with two components:
- A reward model that scores completed responses and defines the optimization objective, and
- A value function (critic) that estimates expected future rewards to compute low-variance advantage estimates.
The training process in PPO is primarily guided by a learned value function that is optimized using the critic.
In production or experimental settings, however, this critic brings about higher memory requirements, higher computational costs, and additional tuning. It can be expensive to train and maintain a reliable value model, especially when GPU resources are limited, iteration times are short, or reward criteria change quickly.
Group Relative Preference Optimization (GRPO) is another method that eliminates the value model from PPO and derives advantages by comparing multiple responses generated for the same prompt. This architecture often minimizes resource consumption, optimizes scattered training, and reduces the likelihood of instability caused by undertrained critics.
DeepSeek has adopted GRPO in the training pipeline of DeepSeek-R1.
Online RL implementation example
This example illustrates a near-online RL with GRPO, and iterative data collection and updates. It is not fully online because it restricts interactions to a fixed prompt set, an iterative RLVR training paradigm in which experience is collected continuously from static or slowly evolving data sources and policy updates are applied in batches.
At the highest level, most online reinforcement learning pipelines for LLMs follow a common interaction and optimization pattern, regardless of the specific training library. The process begins with selecting a sample prompt from the dataset and then obtaining a response from the LLM. Obtain the reward through the verifier and update the policy.
for training_step in range(total_training_steps):
prompts = sample_prompts()
outputs = policy.generate(prompts)
rewards = verifier(outputs)
policy.update(prompts, outputs, rewards)
Let’s walk through this process step by step using the open-source Transformer reinforcement learning library maintained by Hugging Face. It provides reinforcement learning algorithms for transformer-based language models, particularly alignment and preference optimization.
Note: The complete code for this example is available in this Google Colab notebook.
Installation and primary setup
First, install the required libraries for LLM post-training using RL.
!pip install -U -q trl peft math_verify
!pip install unsloth-zoo==2025.9.9
Next, log in to Hugging Face to connect your saved model to your Hugging Face account. Use an access token for login.
from huggingface_hub import notebook_login
notebook_login()
Dataset loading, preferences settings, and pre-trained model selection
A complex, mathematically focused dataset (AI-MO/NuminaMath-TIR) is used in this example. It uses a training procedure similar to that of DeepSeek-R1. The example also uses SYSTEM_PROMPT to tailor the response through a prompt that encourages the reasoning process.
Load the dataset and select the train-test split based on your requirements.
from datasets import load_dataset
dataset_id = 'AI-MO/NuminaMath-TIR'
train_dataset, test_dataset = load_dataset(dataset_id, split=['train[:50%]', 'test[:50%]'])
SYSTEM_PROMPT = (
"A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant "
"first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning "
"process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., "
"<think> reasoning process here </think><answer> answer here </answer>"
)
def make_conversation(example):
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["problem"]},
],
}
train_dataset = train_dataset.map(make_conversation)
test_dataset = test_dataset.map(make_conversation)
print(train_dataset)
print(train_dataset[0]['prompt'])
You can check the count of the loaded dataset with the following command.
train_dataset = train_dataset.remove_columns(['messages', 'problem'])
print(train_dataset)
Dataset({
features: ['solution', 'prompt'],
num_rows: 36220
})
Next, load your model for fine-tuning.
Import torch
from transformers import AutoModelForCausalLM
model_id = "Qwen/Qwen2-0.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)
You can get the trainable parameters count by using LoraConfig.
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
task_type="CAUSAL_LM",
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"],
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
trainable params: 540,672 || all params: 494,573,440 || trainable%: 0.1093
RLVR reward functions
First, you need to implement a structural verification reward that checks whether the model’s output matches the required response format as preferred in the input prompt. Here, you can match the response format to assign a score based on the agent's thinking process.
import re
def format_reward(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think>\s*<answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
rewards_list = [1.0 if match else 0.0 for match in matches]
return [1.0 if match else 0.0 for match in matches]
Now, you have to implement a function to give a correctness reward based on formal verification against a ground-truth mathematical solution. Parse both the model’s answer and the reference solution into LaTeX-based mathematical representations.
Based on the equivalence, assign a correctness reward.
from math_verify import LatexExtractionConfig, parse, verify
def accuracy_reward(completions, **kwargs):
"""Reward function that checks if the completion is the same as the ground truth."""
solutions = kwargs['solution']
completion_contents = [completion[0]["content"] for completion in completions]
rewards = []
for content, solution in zip(completion_contents, solutions):
gold_parsed = parse(solution, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()])
answer_parsed = parse(content, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()])
if len(gold_parsed) != 0:
try:
rewards.append(float(verify(answer_parsed, gold_parsed)))
except Exception:
rewards.append(0.0)
else:
rewards.append(1.0)
return rewards
TRL GRPO model initialization and training
For post-training, the TRL's RL model has two objects. First is GRPOconfig, which provides access to training parameters that can be adjusted to improve training performance. Second is GRPOTrainer; it takes as input the model, reward function, configurations, and a dataset to start the training process.
from trl import GRPOConfig
# Configure training arguments using GRPOConfig
training_args = GRPOConfig(
output_dir="Qwen2-0.5B-GRPO-test-1",
learning_rate=1e-4,
remove_unused_columns=False, # to access the solution column in accuracy_reward
gradient_accumulation_steps=16,
num_train_epochs=4,
bf16=True,
# Parameters that control de data preprocessing
max_completion_length=64, # default: 256
num_generations=2, # default: 8
max_prompt_length=512, # default: 512
# Parameters related to reporting and saving
report_to=["tensorboard"],
logging_steps=10,
push_to_hub=True,
save_strategy="steps",
save_steps=10,
from trl import GRPOTrainer
trainer = GRPOTrainer(
model=model,
reward_funcs=[format_reward, accuracy_reward],
args=training_args,
train_dataset=train_dataset
)
You can start the training by calling the train() function.
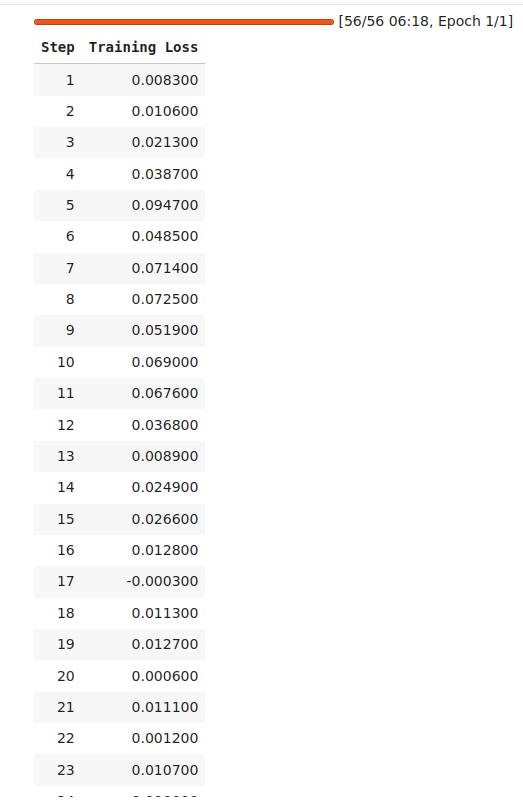
trainer.train()
If you look at the training metrics and results below, you'll see a significant reduction in training loss, indicating successful learning.
Saving the results and model
You can save your results and model in your own Hugging Face space.
trainer.save_model(training_args.output_dir)
trainer.push_to_hub(dataset_name=dataset_id)
The saved results can be visualized on your linked Hugging Face account. You can check the performance metrics column at the link provided by executing the command above.
In GRPO training, the logged metrics summarize optimization stability, generation behavior, and reward-driven learning.
- Loss, gradient norm, and learning rate indicate the magnitude and stability of parameter updates; smaller values suggest convergence.
- Epoch, step, and token counts track overall training progress.
- Completion length statistics and the clipped ratio describe how the model generates responses; shorter, naturally terminated outputs reflect more confident behavior.
- Format and accuracy rewards, along with total reward and reward variance, measure task performance and consistency, with higher rewards indicating improvement.
- Entropy captures policy uncertainty, gradually decreasing as the model becomes more confident and stable.
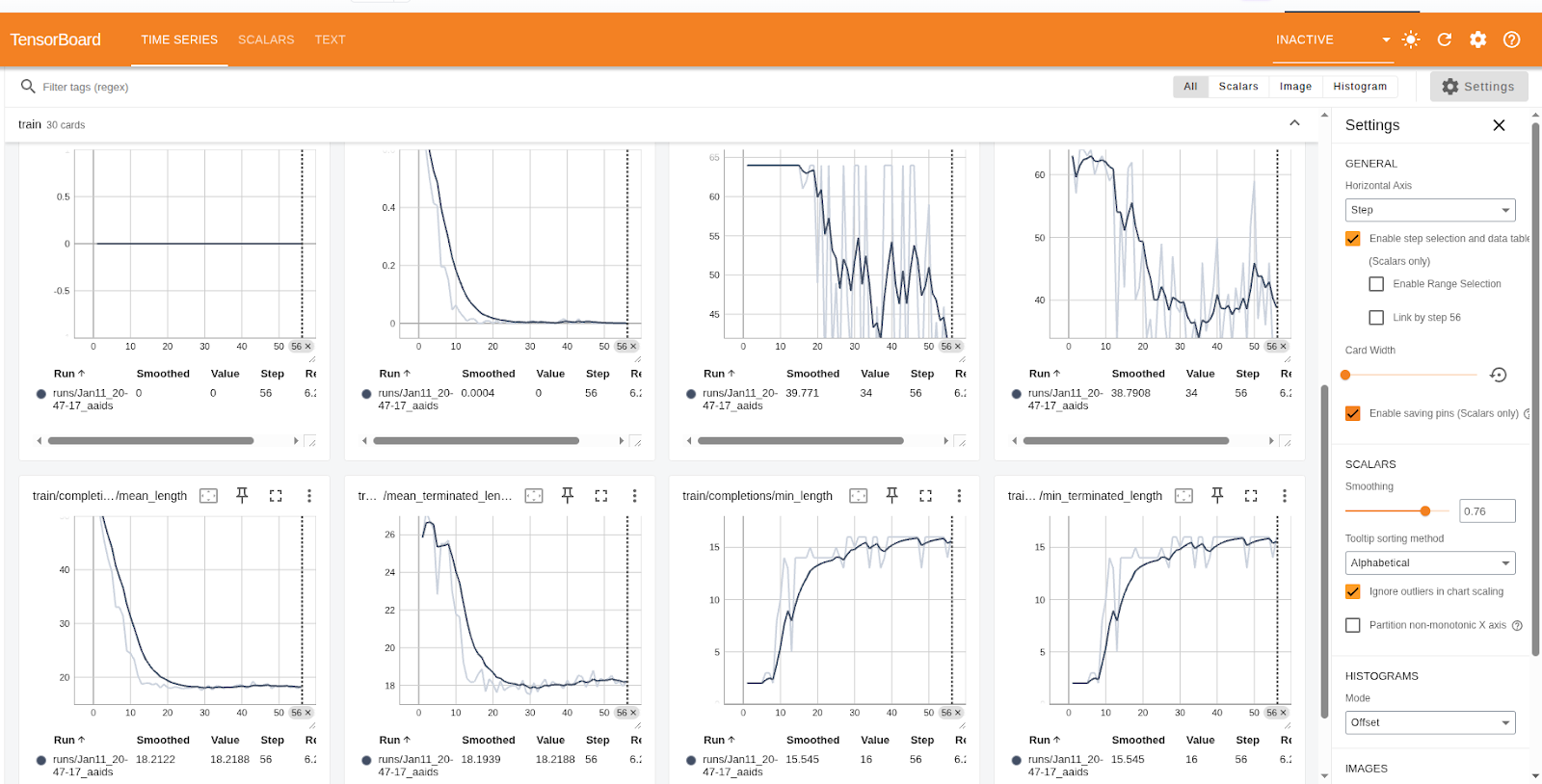
Test and verification
To test the trained model, you need to provide the path to your Hugging Face account, and the trained model can be accessed inside your notebook. To verify, you can generate responses from the untrained and trained models and compare them to analyze the output progress.
"Qwen/Qwen2-0.5B-Instruct" is the untrained model, and “Qwen2-GRPO-Trained-Model” is the trained model of this example. Both can be loaded to view the model response before training. The results from the untrained and trained models are given at the end of this subsection.
model_id = "Qwen/Qwen2-0.5B-Instruct"
trained_model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)
from transformers import AutoTokenizer
model_id = "SulemanSahib/Qwen2-GRPO-Trained-Model"
trained_model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)
trained_tokenizer = AutoTokenizer.from_pretrained(model_id)
import time
def generate_with_reasoning(prompt):
# Build the prompt from the dataset
prompt = " ".join(entry['content'] for entry in prompt)
# Tokenize and move to the same device as the model
inputs = trained_tokenizer(prompt, return_tensors="pt").to(trained_model.device)
# Generate text without gradients
start_time = time.time()
with torch.no_grad():
output_ids = trained_model.generate(**inputs, max_length=500)
end_time = time.time()
# Decode and extract model response
generated_text = trained_tokenizer.decode(output_ids[0], skip_special_tokens=True)
# Get inference time
inference_duration = end_time - start_time
# Get number of generated tokens
num_input_tokens = inputs['input_ids'].shape[1]
num_generated_tokens = output_ids.shape[1] - num_input_tokens
return generated_text, inference_duration, num_generated_tokens
prompt = test_dataset['prompt'][0]
generated_text, inference_duration, num_generated_tokens = generate_with_reasoning(prompt)
prompt_text = " ".join(entry['content'] for entry in prompt)
response_text = generated_text[len(prompt_text):].strip()
print(response_text)
The response obtained before training contains a lot of reasoning, but does not accurately address the mathematical solution. In contrast, the trained model limits the thinking process and focuses on solutions, making LLM use more efficient by reducing generation time and the number of generated tokens.
Even though the mathematical problem is quite complex, the GRPO-trained reasoning has trained the model to formulate the answer correctly. Here is the Google Colab link to the notebook.
You can see the images below, which show the test question presented to finetuned and untrained models and answers of both, before and after post-training using GRPO.



Best practices for Online RL
Online RL systems should use uncertainty-aware sampling, focused preference inquiries, or verifier-initiated feedback to optimize data collection and reduce unwanted or inferior outcomes. You must clearly specify the interaction loop, which includes the environment, actions, and feedback, to drive policy revisions through real-time, realistic interactions rather than static or synthetic proxies.
Policy changes should also be careful and restrained. Employ trust-region techniques, KL regularization, constrained learning rates, and systematic evaluation milestones to avoid behavioral regressions. Reward models and verifiers should also be thoroughly investigated and modified before being declared conclusive.
Online reinforcement learning pipelines also require auditing, recalibration, and fail-safe protocols to ensure alignment and robustness, and to avoid reward signal drift or manipulation.
Organizations can approach online reinforcement learning as a continuous engineering process, monitoring, modifying, and evaluating performance using real-time metrics and standards.
How Patronus AI helps
Patronus AI allows you to train and evaluate AI agents in reinforcement learning environments that closely match real-world production scenarios. The platform is purpose-built to inspect and refine LLMs and autonomous agents through rich execution traces, explicit feedback, and verifiable reward signals. It allows you to identify precisely where an agent performs correctly or breaks down, and then iteratively improve its behavior based on that evidence.
RL environments built around real operational tasks
Rather than relying on synthetic benchmarks, Patronus AI offers RL environments built around real operational tasks such as software development, SQL query generation, customer support workflows, financial question answering, and trading simulations. Because these tasks reflect real use cases, improvements achieved here carry over directly to real systems.
Every environment provides automated and objectively verifiable reward signals. Instead of subjective human scoring, Patronus determines correctness using test suites, database validation, or schema-level checks. This approach produces signals that are stable, repeatable, and suitable for large-scale evaluation.
Cross-environment consistency
Patronus supports a wide range of reinforcement learning environment types, including:
- Coding and debugging agents
- SQL and database question answering
- Customer service and support flows
- Financial data insight generation
- Trading or simulated market interaction
- Web navigation and e-commerce task agents
Each environment includes structured evaluation logic that verifies correctness, execution order, error handling, and output consistency.
Agents trained within one Patronus environment can also generalize their learned behaviors to other environments. For example, a coding agent that learns to generate clean, error-free, and well-structured code carries learned behavior into different problem domains. This cross-environment consistency reduces overfitting and promotes stronger generalization.
{{banner-dark-small-1-rle="/banners"}}
Final thoughts
Online reinforcement learning significantly changes how we align and maintain LLMs, enabling them to continuously adjust based on feedback and evolving strategies. This enables models to adapt to changing user requirements and distributional shifts, but it also presents challenges like reward misspecification, feedback instability, and safety drift, necessitating meticulous reward design and cautious updates.
As a result, more and more practical systems are using hybrid methods that combine RLHF for subjective alignment with RLVR for accuracy that can be scaled and verified. Platforms like Patronus AI illustrate how production-grade online reinforcement learning can transform alignment into a continuous, quantifiable engineering process instead of a singular training phase.

