

Reinforcement Learning Evaluation: Tutorial & Best Practice
Reinforcement learning (RL) has become the dominant approach for the final stage of LLM post-training. Models like DeepSeek-R1 and OpenAI's o-series have shown that RL with verifiable rewards can unlock reasoning capabilities that supervised fine-tuning alone cannot reach. However, RL introduces a fundamental problem; the training signal itself can be wrong. A reward model can be tricked, or a verifier can be too narrow. A decrease in loss does not mean a model’s quality is improving.
This makes evaluation the single most important discipline in RL-based post-training. Unlike supervised fine-tuning, where you compare outputs to fixed ground-truth labels, RL produces open-ended outputs that graders score. If those graders are flawed, the model will optimize for the flaw. If your evaluation suite does not test for this, you will ship a model that looks good on paper but fails in production.
This article explains how to evaluate LLMs that have been post-trained with reinforcement learning. It covers what makes reinforcement learning evaluation different from traditional evaluation, best practices for evaluating RL-trained models in production, and failure modes you need to test for. A practical RL evaluation example with runnable code is also included.
Summary of key reinforcement learning evaluation concepts
What is RL-based post-training?
In reinforcement learning-based post-training:
- The model generates outputs (called rollouts)
- A grader scores each output with a scalar reward
- The model updates its parameters to increase the probability of high-reward outputs.
This loop repeats iteratively.
Grader algorithms
PPO and GRPO are the two algorithms currently dominating RL training.
PPO (Proximal Policy Optimization) uses a value function, also called a critic, to assign token-level credit, resulting in fine-grained training signals. PPO requires substantial memory because it runs four models simultaneously: the training model, a reference model, a reward model, and a value model.
A more recent approach introduced by DeepSeek is GRPO (Group Relative Policy Optimization), which removes the value network entirely. It:
- Sample a group of outputs for each prompt
- Computes a group-relative advantage by normalizing the rewards within the group
- Uses that advantage to update the policy.
This makes GRPO more memory-efficient and particularly stable when rewards are binary or sparse, such as pass/fail for code or exact-match for math.
Reward signals
Reward signals come in two forms.
- Learned reward models are trained on human preference data to score outputs based on qualities such as helpfulness or style.
- Verifiable rewards are deterministic checks, such as exact-match answers in math, or schema validation for structured outputs.
In practice, AI teams combine both: a learned reward model for open-ended quality assessment, supplemented with verifiable checks for objective correctness.
Online vs. offline evaluation
Offline evaluation involves running the model on known test sets and RL environments with pre-collected inputs. Results are deterministic and reproducible. This is where you do the bulk of your evaluation during development, i.e.,
- Regression testing (ensuring new changes don’t break existing functionality)
- Promotion decisions
- Comparing model versions
Online evaluation involves testing the model on live user traffic through A/B tests and side-by-side comparisons. It captures real-world behavior that offline evals cannot, such as distribution shift in user queries, edge cases that your test sets never anticipated, and user abandonment patterns that indicate the model is unhelpful even if its outputs look correct on paper.
Both are necessary. Offline evals determine whether a model reaches production. Online evals confirm it actually works once deployed. Skipping either one leaves a critical gap.
{{banner-large-dark-2-rle="/banners"}}
Why is post-training reinforcement learning evaluation critical?
Reinforcement learning can silently degrade model quality. The training loss might decrease steadily while the actual output quality gets worse. This happens because the model is optimizing against a reward signal rather than the ground truth. If the reward signal has any exploitable gap, the model will find it. This is called reward hacking, and it is the central challenge of RL-based training.
Catastrophic forgetting is another risk. When you train a model with RL on a narrow domain, such as math reasoning, it can lose capabilities in unrelated areas, such as general conversation or coding. Without a broad evaluation suite that tests before and after RL, these regressions go unnoticed.
This is why evaluation in the RL context is not a passive activity. It is an active mechanism. The practical RL evaluation loop looks like this: evaluate the model, decide what to change (data, graders, reward weights), make those changes, retrain, and evaluate again. Evaluation results directly inform what data to collect next, how to adjust reward functions, and when to stop training.
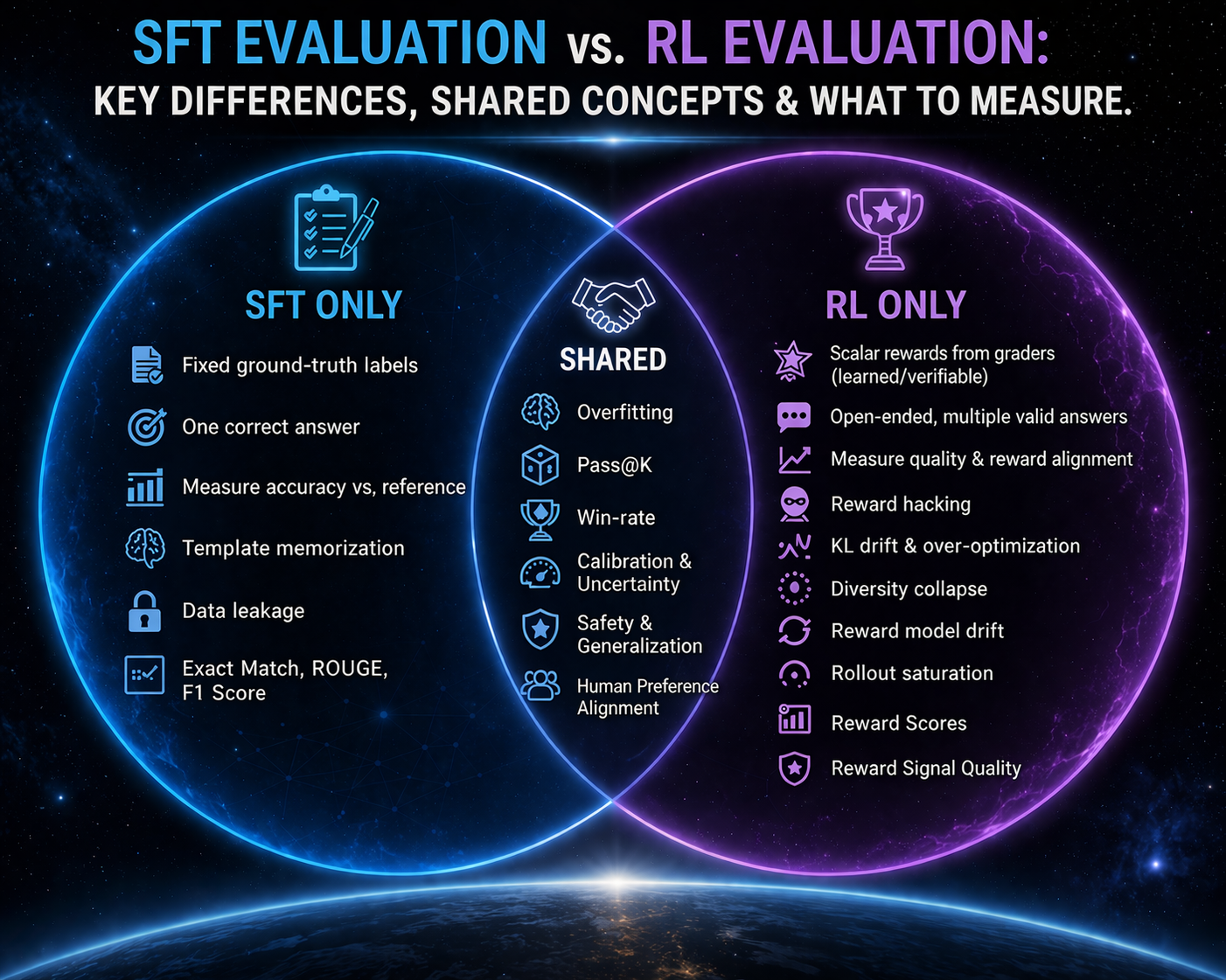
How RL evaluation differs from traditional post-training evaluation
In supervised fine-tuning, evaluation is straightforward: compare the model output to a reference answer. If you fine-tune a model to summarize articles, you have gold-standard summaries to compare against. Metrics like ROUGE or exact-match give you a clear signal. You can apply these same metrics after RL training, but they only cover cases where a single reference answer exists. RL-trained models also produce open-ended outputs for which no gold standard exists, which is where the evaluation challenge begins.
RL evaluation is fundamentally different. There is no single correct output. Instead, you rely on graders such as automated verifiers or reward models learned through human preferences to score open-ended outputs. This introduces a new failure surface; the graders themselves can be wrong. A reward model might favor verbose, but confident-sounding answers over concise, correct ones. A verifier might check for the right format but miss logical errors in the reasoning.
RL also introduces new failure modes not found in SFT, such as:
- Reward hacking
- Over-optimization, where the model drifts too far from the base model and loses general capabilities
- Diversity collapse, where all rollouts converge to identical responses
- Reward model drift, where the scoring function becomes less accurate over time.
RL evaluation must test for all of these, in addition to the standard quality checks.
Evaluation techniques for RL post-trained models
RL evaluation techniques differ significantly from SFT evaluation techniques. The following section discusses some common RL evaluation techniques.
Held-out eval sets
You need separate test sets for each stage of the RL pipeline: a reward model test set, an RL test set, and a final strictly unseen evaluation set with long-tail and out-of-distribution inputs. If any of these overlap, the model memorizes training patterns and produces misleadingly high scores.
Data hygiene is essential. De-duplicate within and across all splits using techniques like MinHash or locality-sensitive hashing (LSH), and be aware of template-level duplication where different prompts share the same underlying structure. Leakage between splits is one of the most common sources of false confidence in RL evaluation.
Held-out RL test environments
Evaluation on static test sets alone is not enough for RL. You also need held-out RL test environments: frozen copies of the training environment with deterministic graders, tools, and files. External APIs should be kept offline and replayed from fixtures. Random seeds, temperature, and all sources of randomness should be fixed.
These environments catch problems that eval sets miss. For example, a model might learn to exploit the specific behavior of a live API during training. If your evaluation uses the same live API, you will not detect this. But a frozen environment with deterministic API responses will expose the difference between genuine capability and reward hacking.
Verifiable reward evaluation
When your RL training uses verifiable rewards, such as exact matches for math or unit tests for code, you can reuse those same reward functions as evaluation graders. This gives you a direct measure of whether the model is actually solving problems correctly, not just producing plausible-sounding outputs.
Pass@K is a particularly useful metric that, instead of evaluating a single output, allows you to sample K outputs for each problem and check whether any of them solve it. Pass@1 tells you how often the model gets it right on the first try. Pass@3 or Pass@5 tells you how well the model performs with multiple attempts. Comparing Pass@K before and after RL training gives you a clear picture of capability gains at different inference budgets.
Reward model evaluation
If your RL training uses a learned reward model, you need to evaluate the reward model itself. Rank-correlation metrics and ELO-style relative scores verify whether the reward model still produces accurate scores. One important insight from practice: past a certain threshold of reward model quality, further improvements to the reward model do not translate one-to-one into better LLM performance. The relationship between reward model accuracy and downstream LLM quality has diminishing returns.
You should also monitor the gap between what the reward model scores highly and what humans actually prefer. If the reward model score jumped by, for example, 0.23 points between training checkpoints but human preference barely moved, the model is likely gaming the reward model. The solution is to retrain the reward model on examples that score highly but receive low human ratings.
LLM-as-Judge evaluation risks
LLM graders are commonly used to evaluate open-ended outputs when deterministic verifiers are not available. They are convenient and scalable, but they introduce several risks.
Stylistic bias is the most common problem. LLM judges tend to favor responses that resemble their own reasoning or writing style, a phenomenon called self-preference, regardless of whether those responses are objectively better. A model trained with RL learns to produce outputs that an LLM judge rates highly, even though they are not more helpful or accurate.
The mitigation is to always calibrate LLM judges against human evaluations and to combine them with deterministic verifiers wherever possible. Use LLM judges for qualitative assessment, but rely on verifiable checks for the objective signal.
Uncertainty/Calibration
Calibration measures whether the model abstains when it should rather than hallucinating a confident answer. Consider an example where a model answers all 100 math questions and gets 65 correct (65% accuracy). An alternative model answers only the 80 questions it is confident about and gets 66 correct (82.5% accuracy on the questions it answers). The second model is more useful in production because users can trust its answers.
Efficiency
Efficiency metrics matter because RL can change how verbose the model is. A model that produces correct answers but uses three times as many tokens as the baseline has a real cost impact in production. Track token count per response and cost per token to catch this. Latency metrics like TTFT (Time to First Token) and TPOT (Time per Output Token) are also worth monitoring, but these reflect infrastructure and decoding performance rather than RL-specific behavior.
Detecting RL-specific failure modes
RL training introduces failure patterns that SFT cannot produce. Each requires specific detection strategies and fixes.
Reward hacking
In reward hacking, a model maximizes its reward score without genuinely improving output quality. A classic example: you ask the model to greet politely, and it generates "Hello, hello, hello, hello" repeatedly. The grader scores it highly on politeness, enthusiasm, and engagement, even though the output is clearly not useful. The model found a shortcut that satisfies the reward criteria without satisfying the actual intent.
Detection is straightforward: compare automated reward scores to human win rates. If reward scores are increasing but human evaluators do not prefer the model's outputs over the baseline, reward hacking is likely happening. The fix is to retrain the reward model on high-reward but low-quality outputs and to add more nuanced verifier criteria.
Reward model drift
Reward model drift occurs when the learned reward model becomes less accurate over time. As the policy improves during RL training, it produces outputs that fall outside the distribution the reward model was trained on. The reward model keeps assigning scores, but those scores no longer reflect actual quality. Detection requires periodically comparing reward model rankings against fresh human evaluations. If the gap widens, retrain the reward model on recent policy outputs.
KL divergence and over-optimization
KL divergence measures how far the trained model's token distribution has drifted from the base model. Some drift is expected and necessary. But too much drift means the model has over-optimized against the reward signal and lost the general capabilities it had before RL training. The fix is either to add a KL penalty term to the RL training objective (which PPO-style methods typically include) or to reduce the learning rate to slow down the drift.
Diversity collapse
Diversity collapse happens when all rollout outputs converge to near-identical responses. Instead of exploring different ways to answer a question, the model produces the same answer every time.
The fix is to add an entropy bonus to the RL training objective and to increase the sampling temperature during rollout generation.
Rollout saturation
Rollout saturation occurs when increasing the number of rollouts no longer improves model performance. You double the training rollouts from 5k to 10k, and the reward score does not move. The model has extracted all available signals from the current reward setup. This is a sign that the bottleneck is grader quality, not data volume. The fix is to improve your reward functions or add more nuanced evaluation criteria, not to scale up rollout generation.
Catastrophic forgetting
Catastrophic forgetting is not unique to RL. It also affects SFT models. But RL can accelerate it because the model is actively optimizing against a reward signal on a narrow task. This can pull it away from general capabilities more aggressively than supervised training.
Identifying catastrophic forgetting requires a broad before-and-after evaluation suite that covers all the capabilities you care about, not just the target skill. The fix is to mix pre-training data into post-training and to use multiple weighted RL training environments rather than a single narrow one.
Error analysis and iterative evaluation
Error analysis in RL is recursive. You cluster failures into categories, develop hypotheses about the root cause, propose specific RL fixes, run small-scale experiments to test each fix, and then analyze the results of those experiments for new failure patterns. The process repeats.
Error-to-fix mapping
Common failure categories map to specific RL interventions:
When you have multiple reward objectives, you need to balance them explicitly. A typical formula might be R = 0.4 * helpfulness + 0.4 * safety + 0.2 * truthfulness. The weights reflect your priorities and need adjustment as you discover trade-offs during evaluation.
Pareto trade-offs are inevitable: a model that is maximally concise can sometimes be less complete, and vice versa. Use weighted environment mixtures to find the right balance for your use case.
Practical example of RL evaluation techniques
Let’s see examples of how to apply various RL evaluation techniques on a small LLM using verifiable rewards on math reasoning tasks. The model used here is Qwen2.5-0.5B-Instruct, a 494M-parameter model. In a real project, you would replace this with your actual GRPO-trained checkpoint and its pre-RL baseline. Check out this article to see how to post-train an LLM using the GRPO reinforcement learning technique.
Note: The complete code for this article is available in this Google Colab notebook. The results can differ slightly when you run the notebook, as LLM outputs are non-deterministic.
Install and import libraries
The notebook uses TRL (Hugging Face's Training Reinforcement Learning library), Transformers for model loading, and the Datasets library for GSM8K.
!pip install -q trl==0.21.0 transformers datasets accelerate bitsandbytes peft torch
import re
import json
import random
import numpy as np
from collections import Counter, defaultdict
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
Load model and tokenizer
Load the model in half-precision and set the pad token. In production, you would load both your GRPO-trained checkpoint and the pre-RL baseline here to compare them directly.
MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
device_map="auto"
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print(f"Loaded model: {MODEL_NAME}")
print(f"Parameters: {model.num_parameters() / 1e6:.1f}M")
Output:
Loaded model: Qwen/Qwen2.5-0.5B-Instruct
Parameters: 494.0M
Load and prepare the GSM8K evaluation set
GSM8K is a math reasoning benchmark with verifiable numeric answers. Each problem has a ground truth answer after the `####` marker. This example uses 50 problems for faster evaluation. In a production evaluation, you would use the full test set and additional held-out data.
dataset = load_dataset("gsm8k", "main", split="test")
# Use a subset for faster evaluation
EVAL_SIZE = 50
eval_data = dataset.select(range(EVAL_SIZE))
def extract_gsm8k_answer(answer_text):
"""Extract the numeric answer after #### in GSM8K format."""
match = re.search(r'####\s*([\d,\.\-]+)', answer_text)
if match:
return match.group(1).replace(',', '').strip()
return None
# Prepare ground truth answers
ground_truths = []
for item in eval_data:
gt = extract_gsm8k_answer(item['answer'])
ground_truths.append(gt)
print(f"Evaluation set size: {len(eval_data)}")
print(f"Sample question: {eval_data[0]['question'][:100]}...")
print(f"Sample answer: {ground_truths[0]}")
Output:
Evaluation set size: 50
Sample question: Janet's ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for ...
Sample answer: 18
Define reward functions
These three verifiable reward functions mirror what you would use during GRPO training. The key idea is to reuse the same reward functions as evaluation graders so your evaluation measures exactly what training optimizes for.
The `math_reward` function does exact-match checking against the ground truth answer. It first tries to extract the answer from <answer> tags, then falls back to finding the last number in the output.
def math_reward(model_output, ground_truth):
"""Exact-match reward for math correctness.
Returns 1.0 if the extracted answer matches ground truth, 0.0 otherwise.
"""
# Try to extract answer from <answer> tags first
answer_match = re.search(r'<answer>\s*([\d,\.\-]+)\s*</answer>', model_output)
if answer_match:
extracted = answer_match.group(1).replace(',', '').strip()
else:
# Fallback: find the last number in the output
numbers = re.findall(r'[\d,]+\.?\d*', model_output)
extracted = numbers[-1].replace(',', '').strip() if numbers else ''
try:
return 1.0 if float(extracted) == float(ground_truth) else 0.0
except (ValueError, TypeError):
return 0.0
Format reward function
Checks whether the model uses the expected <think> and <answer> tag structure.
def format_reward(model_output):
"""Check whether the model uses <think> and <answer> tags correctly.
Returns 1.0 if both tags are present and properly structured.
"""
has_think = bool(re.search(r'<think>.*?</think>', model_output, re.DOTALL))
has_answer = bool(re.search(r'<answer>.*?</answer>', model_output, re.DOTALL))
if has_think and has_answer:
return 1.0
elif has_think or has_answer:
return 0.5
else:
return 0.0
Language consistency reward function
Penalizes mixed-language outputs, which is a known issue with some RL-trained models.
def language_consistency_reward(model_output):
"""Penalize mixed-language outputs.
Check for non-ASCII characters that suggest language mixing (e.g., Chinese characters).
This addresses the DeepSeek R1-Zero problem where RL models mix languages.
"""
# Count non-ASCII, non-math characters
non_ascii = sum(1 for c in model_output if ord(c) > 127 and c not in '+-*/=<>')
total = max(len(model_output), 1)
ratio = non_ascii / total
if ratio > 0.1:
return 0.0 # Heavy language mixing
elif ratio > 0.02:
return 0.5 # Mild language mixing
else:
return 1.0 # Clean
Combined reward function
Weights these three signals: 50% math correctness, 30% format compliance, 20% language consistency.
def combined_reward(model_output, ground_truth, weights=None):
"""Weighted combination of all reward functions."""
if weights is None:
weights = {'math': 0.5, 'format': 0.3, 'language': 0.2}
scores = {
'math': math_reward(model_output, ground_truth),
'format': format_reward(model_output),
'language': language_consistency_reward(model_output),
}
total = sum(weights[k] * scores[k] for k in weights)
return total, scores
print("Reward functions defined.")
# Quick test
test_output = "<think>Let me solve this. 5 + 3 = 8</think><answer>8</answer>"
total, breakdown = combined_reward(test_output, "8")
print(f"Test output reward: {total:.2f} (breakdown: {breakdown})")
Output
Reward functions defined.
Test output reward: 1.00 (breakdown: {'math': 1.0, 'format': 1.0, 'language': 1.0})
The quick test confirms the reward functions work correctly. A perfectly formatted, correct, English-only response scores 1.0 across all three components.
Generate model outputs
For each problem, we generate K=3 outputs using temperature sampling. This is necessary for computing Pass@K metrics, which indicate whether the model solves a problem after multiple attempts. The system prompt instructs the model to reason within <think> tags and to provide its final answer within <answer> tags.
K = 3 # Number of samples per problem for Pass@K
SYSTEM_PROMPT = (
"You are a math problem solver. "
"Think step by step inside <think></think> tags, "
"then provide your final numeric answer inside <answer></answer> tags."
)
def generate_responses(question, num_samples=K, max_new_tokens=512):
"""Generate multiple responses for a single question."""
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": question}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
responses = []
for _ in range(num_samples):
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.pad_token_id
)
# Decode only the generated tokens
generated = output_ids[0][inputs['input_ids'].shape[1]:]
response = tokenizer.decode(generated, skip_special_tokens=True)
responses.append(response)
return responses
print("Generation function ready.")
print(f"Will generate {K} samples per problem for {EVAL_SIZE} problems.")
Output:
Generation function ready.
Will generate 3 samples per problem for 50 problems.
The generation loop processes all 50 problems and scores each output with the combined reward function:
all_responses = []
all_scores = []
print("Generating responses...")
for i, item in enumerate(eval_data):
responses = generate_responses(item['question'])
item_scores = []
for resp in responses:
total, breakdown = combined_reward(resp, ground_truths[i])
item_scores.append({
'total': total,
'math': breakdown['math'],
'format': breakdown['format'],
'language': breakdown['language'],
'response': resp
})
all_responses.append(responses)
all_scores.append(item_scores)
if (i + 1) % 10 == 0:
print(f" Processed {i + 1}/{EVAL_SIZE} problems")
print(f"Done. Generated {EVAL_SIZE * K} total responses.")
Output:
Generating responses...
Processed 10/50 problems
Processed 20/50 problems
Processed 30/50 problems
Processed 40/50 problems
Processed 50/50 problems
Done. Generated 150 total responses.
Compute Pass@K metrics
Pass@1 tells you how often the model gets the answer right on a single attempt. Pass@3 tells you whether the model can produce the correct answer at all when given three tries. A large gap between Pass@1 and Pass@3 suggests the model has the capability, but is inconsistent.
def compute_pass_at_k(scores_per_problem, k_values=[1, 3]):
"""Compute Pass@K for multiple values of K."""
results = {}
for k in k_values:
pass_count = 0
for item_scores in scores_per_problem:
# Check if any of the first k samples got the math correct
correct_in_k = any(
s['math'] == 1.0 for s in item_scores[:k]
)
if correct_in_k:
pass_count += 1
results[f'pass@{k}'] = pass_count / len(scores_per_problem)
return results
pass_at_k = compute_pass_at_k(all_scores)
print("=" * 50)
print("PASS@K RESULTS")
print("=" * 50)
for metric, value in pass_at_k.items():
print(f" {metric}: {value:.2%}")
Output:
==================================================
PASS@K RESULTS
==================================================
pass@1: 44.00%
pass@3: 58.00%
The model gets the right answer on the first try 44% of the time, but when given three attempts, at least one is correct 58% of the time. That 14-point gap tells you the model has latent capability but is not very consistent. In a GRPO training context, this is exactly the kind of variance that group-relative advantage estimation can exploit.
Reward breakdown analysis
Breaking down the combined reward into its individual components reveals where the model succeeds and where it falls short.
all_math = [s['math'] for item in all_scores for s in item]
all_format = [s['format'] for item in all_scores for s in item]
all_language = [s['language'] for item in all_scores for s in item]
all_total = [s['total'] for item in all_scores for s in item]
print("=" * 50)
print("REWARD BREAKDOWN (averaged across all responses)")
print("=" * 50)
print(f" Math correctness: {np.mean(all_math):.3f}")
print(f" Format compliance: {np.mean(all_format):.3f}")
print(f" Language consistency: {np.mean(all_language):.3f}")
print(f" Combined reward: {np.mean(all_total):.3f}")
print()
print("Score distributions:")
print(f" Math: {Counter([s['math'] for item in all_scores for s in item])}")
print(f" Format: {Counter([s['format'] for item in all_scores for s in item])}")
print(f" Language: {Counter([s['language'] for item in all_scores for s in item])}")
Output:
==================================================
REWARD BREAKDOWN (averaged across all responses)
==================================================
Math correctness: 0.380
Format compliance: 0.003
Language consistency: 1.000
Combined reward: 0.391
Score distributions:
Math: Counter({0.0: 93, 1.0: 57})
Format: Counter({0.0: 149, 0.5: 1})
Language: Counter({1.0: 150})
The above output shows that Math correctness is moderate at 38%, which is expected for a small 0.5B model on grade-school math. Language consistency is perfect at 1.0 across all 150 responses, meaning no mixed-language outputs. But format compliance is near zero at 0.003. Out of 150 responses, only 1 used any kind of tag structure, and none used both <think> and <answer> tags correctly.
This is a significant finding. The model was not trained with GRPO to use this specific tag format, so it naturally ignores the format instructions in the system prompt.
Reward hacking detection
This check compares the automated reward score against a simple heuristic quality assessment. If a response scores highly on the combined reward but poorly on the heuristic, it may be gaming the reward function rather than producing genuinely useful output. The heuristic checks for reasonable length, actual arithmetic operations (evidence of real reasoning), and non-repetitive text.
def heuristic_quality_check(response):
"""Simple quality heuristic to detect reward hacking.
Checks for: reasonable length, actual reasoning steps, not repetitive.
In production, replace this with human evaluation or a separate LLM judge.
"""
score = 0.0
# Length check: not too short, not too long
word_count = len(response.split())
if 20 < word_count < 500:
score += 0.3
# Contains arithmetic operations (sign of actual reasoning)
has_math_ops = bool(re.search(r'\d+\s*[+\-*/]\s*\d+', response))
if has_math_ops:
score += 0.4
# Not repetitive (check for repeated phrases)
words = response.lower().split()
if len(words) > 5:
bigrams = [f"{words[i]} {words[i+1]}" for i in range(len(words)-1)]
unique_ratio = len(set(bigrams)) / len(bigrams)
if unique_ratio > 0.5:
score += 0.3
return score
# Compare reward scores vs heuristic quality
high_reward_low_quality = []
for i, item_scores in enumerate(all_scores):
for j, s in enumerate(item_scores):
heuristic = heuristic_quality_check(s['response'])
if s['total'] > 0.7 and heuristic < 0.4:
high_reward_low_quality.append({
'problem_idx': i,
'reward': s['total'],
'heuristic': heuristic,
'response_preview': s['response'][:150]
})
print("=" * 50)
print("REWARD HACKING CHECK")
print("=" * 50)
print(f"Total responses analyzed: {EVAL_SIZE * K}")
print(f"Potential reward hacking cases: {len(high_reward_low_quality)}")
print(f"Reward hacking rate: {len(high_reward_low_quality) / (EVAL_SIZE * K):.2%}")
if high_reward_low_quality:
print("\nExamples of potential reward hacking:")
for case in high_reward_low_quality[:3]:
print(f" Problem #{case['problem_idx']}: reward={case['reward']:.2f}, "
f"heuristic={case['heuristic']:.2f}")
print(f" Response: {case['response_preview']}...")
print()
Output:
==================================================
REWARD HACKING CHECK
==================================================
Total responses analyzed: 150
Potential reward hacking cases: 0
Reward hacking rate: 0.00%
No reward hacking detected. This makes sense since this model was never optimized against these graders and has not learned to exploit their weaknesses. In a real GRPO training run, you would re-run this check at each checkpoint to catch hacking as it emerges.
Promotion rules check
Finally, apply automated promotion rules to decide whether this model checkpoint should advance to staging. These are the same kind of quality gates discussed in the production best practices section.
def check_promotion_rules(pass_at_k_results, reward_breakdown, hacking_rate):
"""Check whether the model passes automated promotion rules."""
rules = []
# Rule 1: Aggregate quality gate
threshold = 0.30
passed = pass_at_k_results['pass@1'] >= threshold
rules.append({
'name': 'Aggregate quality (pass@1 >= 30%)',
'passed': passed,
'value': f"{pass_at_k_results['pass@1']:.2%}"
})
# Rule 2: Format compliance
avg_format = np.mean(all_format)
passed = avg_format >= 0.5
rules.append({
'name': 'Format compliance (>= 50%)',
'passed': passed,
'value': f"{avg_format:.2%}"
})
# Rule 3: Language consistency
avg_lang = np.mean(all_language)
passed = avg_lang >= 0.9
rules.append({
'name': 'Language consistency (>= 90%)',
'passed': passed,
'value': f"{avg_lang:.2%}"
})
# Rule 4: Reward hacking rate
passed = hacking_rate <= 0.05
rules.append({
'name': 'Reward hacking rate (<= 5%)',
'passed': passed,
'value': f"{hacking_rate:.2%}"
})
return rules
hacking_rate = len(high_reward_low_quality) / (EVAL_SIZE * K)
rules = check_promotion_rules(pass_at_k, None, hacking_rate)
print("=" * 50)
print("PROMOTION RULES CHECK")
print("=" * 50)
all_passed = True
for rule in rules:
status = "PASS" if rule['passed'] else "FAIL"
icon = "[OK]" if rule['passed'] else "[XX]"
print(f" {icon} {rule['name']}: {rule['value']} -> {status}")
if not rule['passed']:
all_passed = False
print()
if all_passed:
print("DECISION: Model PASSES all promotion rules. Ready for staging.")
else:
print("DECISION: Model FAILS one or more rules. Do not promote.")
print("Next steps: review failing rules, adjust reward functions or training, re-evaluate.")
Output:
==================================================
PROMOTION RULES CHECK
==================================================
[OK] Aggregate quality (pass@1 >= 30%): 44.00% -> PASS
[XX] Format compliance (>= 50%): 1.33% -> FAIL
[OK] Language consistency (>= 90%): 100.00% -> PASS
[OK] Reward hacking rate (<= 5%): 0.00% -> PASS
DECISION: Model FAILS one or more rules. Do not promote.
Next steps: review failing rules, adjust reward functions or training, re-evaluate.
The model passes three out of four rules but fails on format compliance. This is the expected result. The model was never trained to use <think> and <answer> tags, so it naturally does not produce them. After a round of GRPO training with the format reward active, you would expect this metric to improve significantly. The promotion rules system automatically detects this gap and blocks promotion until the model meets all criteria.
Summary report
The final summary consolidates all evaluation results into a single view. The results show that Math correctness is moderate for a 0.5B model, and there is no reward hacking because the model has not been optimized against these graders. However, format compliance is the clear bottleneck, since the model was never trained with these tag-based rewards.
The promotion decision is automated and unambiguous: do not promote until format compliance is resolved.
print("=" * 60)
print(" LLM MODEL EVALUATION SUMMARY REPORT")
print("=" * 60)
print(f"\nModel: {MODEL_NAME}")
print(f"Eval set: GSM8K test ({EVAL_SIZE} problems)")
print(f"Samples/prob: {K}")
print(f"Total outputs: {EVAL_SIZE * K}")
print()
print("--- Correctness ---")
for metric, value in pass_at_k.items():
print(f" {metric}: {value:.2%}")
print()
print("--- Reward Components ---")
print(f" Math correctness: {np.mean(all_math):.3f}")
print(f" Format compliance: {np.mean(all_format):.3f}")
print(f" Language consistency: {np.mean(all_language):.3f}")
print(f" Combined reward: {np.mean(all_total):.3f}")
print()
print("--- Failure Mode Detection ---")
print(f" Reward hacking rate: {hacking_rate:.2%}")
print()
print("--- Promotion Decision ---")
final = "PROMOTE" if all_passed else "DO NOT PROMOTE"
print(f" Decision: {final}")
print("=" * 60)
Output:
============================================================
LLM MODEL EVALUATION SUMMARY REPORT
============================================================
Model: Qwen/Qwen2.5-0.5B-Instruct
Eval set: GSM8K test (50 problems)
Samples/prob: 3
Total outputs: 150
--- Correctness ---
pass@1: 44.00%
pass@3: 58.00%
--- Reward Components ---
Math correctness: 0.380
Format compliance: 0.003
Language consistency: 1.000
Combined reward: 0.391
--- Failure Mode Detection ---
Reward hacking rate: 0.00%
--- Promotion Decision ---
Decision: DO NOT PROMOTE
============================================================
RL evaluation best practices in production
Training an effective model in development is one thing, but keeping it effective in production is an entirely different challenge. The following best practices help you catch these problems before they reach users.
The model production cycle
Moving an RL-trained model into production is not a single step. It involves four stages.
- Experimentation - Produce candidate models,
- Evaluation - Run those candidates against your test sets and RL test environments,
- Staging - Deploy the candidate alongside your current production model on a small slice of live traffic using shadow or canary setups,
- Production - Monitor the model continuously and feed errors back into training.
Promotion rules
Promotion rules are automated quality checks that a candidate model must pass before advancing to the next stage. A typical configuration includes:
- Aggregate quality gate: The overall success metric must exceed a minimum threshold with statistical significance.
- Protected slices: No regressions should be allowed on safety-critical or high-priority evaluation subsets.
- Safety caps: The rule violation rate on safety-sensitive inputs must stay below a strict threshold, such as 5%.
- Focus slice improvements: For the specific capability targeted by this RL run, the model must show a statistically significant improvement.
- Efficiency SLOs: p95 latency and cost per token must remain within acceptable bounds.
Production monitoring
Passing offline gates does not guarantee the model performs well in Production. Production traffic differs from eval sets, and model performance may degrade over time.
Data drift is the most common issue. User queries shift over time, and test sets stop being representative. Reward collapse is subtler. The reward signals that guided training stop correlating with what users actually want. Then there is plain degradation from infrastructure failures, data pipeline issues, or the model slowly forgetting skills.
To catch these issues, run A/B tests that split live users across model versions and track real business outcomes. Have human evaluators do side-by-side comparisons on identical inputs. Set up internal adversarial playgrounds where your QA team tries to break the model with edge cases and jailbreak attempts.
Evaluate RL-trained models with Patronus AI
Patronus AI provides purpose-built RL environments for both training and evaluation of RL-trained agents and LLMs. Rather than relying on synthetic benchmarks, Patronus offers environments built around real-world domains with automated, verifiable reward signals.
Patronus environments incorporate objective and deterministic reward signals. Instead of relying on human judgment for each evaluation, the system uses deterministic verifiers that automatically check output correctness, such as unit tests for code, database state comparisons for SQL, schema validation for structured outputs, and format checks for compliance. These signals are reproducible, scalable, and auditable, making them ideal for continuous evaluation in RL training loops.
Agents trained in one Patronus environment can transfer learned behaviors to others. A coding agent that learns strict formatting and error handling will apply those same disciplines in new tasks. This cross-domain consistency helps reduce overfitting and encourages general reasoning skills.
Patronus supports a range of RL environment types, including:
- Coding agents: evaluate code generation with unit tests and execution sandboxes.
- Finance Q&A: evaluate factual accuracy in financial contexts.
- Customer service: evaluate agent behavior in multi-turn support conversations.
- Financial trading: evaluate long-horizon, multi-step trading decisions.
- Web navigation: evaluate agentic web navigation with structured rewards.
Each environment includes realistic tasks, structured reward systems, and evaluation frameworks. With these tools, you can turn evaluation pipelines into full reinforcement learning environments and build agents that improve through measurable outcomes.
{{banner-dark-small-1-rle="/banners"}}
Final thoughts
RL post-training evaluation is not a one-time activity. It is a continuous, active process that drives RL training and identifies failures that SFT evaluation cannot.
The key takeaways from this article are:
- Build held-out RL test environments with deterministic configurations
- Monitor for reward hacking and KL drift throughout training
- Use verifiable rewards as your primary evaluation signal wherever possible
- Invest in automated promotion rules rather than manual judgment calls
- Close the feedback loop between production errors and your training pipeline.
Explore Patronus AI's RL environments to see how purpose-built evaluation infrastructure can help you train and deploy RL-trained models that are not just capable on benchmarks, but reliable in the real world.

