

Reinforcement Learning with Verifiable Rewards: A Complete Guide
Reinforcement Learning with Verifiable Rewards (RLVR) is a specification-driven approach to LLM fine-tuning. It applies a deterministic validation process to the model outputs, relying on predefined checks when calculating the reward. This makes the reward function a true measure of target objectives. RLVR feedback mechanism is objective, reproducible, and auditable.
RLVR thus shifts reward design from approximate models to explicit instructions. The verifier’s ability to optimize the policy depends heavily on the completeness and accuracy of the verification logic. Whereas feedback in RLHF depends on human preference labels, which can be biased and not reproducible.
This article presents the fundamentals of RLVR by establishing a conceptual foundation and explaining its system architecture. It then presents a concrete implementation example code using a training dataset for learning.
Summary of key concepts in reinforcement learning with verifiable rewards
The reward reliability problem in modern reinforcement learning
Reward reliability is a primary problem in the RL learning paradigm. It is the misalignment between the reward function scores or gradings and the actual task objectives. In practice, reward models are based on human feedback, heuristics, or learned models. Therefore, correctness is not a direct criterion for learning. This creates a gap between optimization objectives and actual intentions.
Let’s consider the example of a task where the agent has to complete the maximum number of subtasks in the least time. So the reward can be high scores when time is low, and the number of tasks completed is high. In such situations, agents exploit rewards by repeatedly solving easy tasks to achieve the maximum score in the least time.
This creates a verification gap, in which incomplete coverage of success criteria leads the verifier to accept only certain cases. Thereby failing to achieve the aim of generalization. Consequently, the agent maximizes scores rather than truly accomplishing subtasks, yielding outputs that serve as proxies for the intended optimization objectives.
Learned reward models, such as those used in reinforcement learning with human feedback (RLHF), that train on human preference labels introduce additional issues. They can inherit bias from the training data, degrade under distribution shift, and provide rewards that are difficult to interpret.
RLVR reduces this risk by replacing proxy rewards with deterministic validation. However, this only works when the verifier is complete and correctly specified.
What is RLVR? - Technical explanation
Reinforcement Learning with Verifiable Rewards (RLVR) is a system in which the reward closely adheres to the task rules. The reward function in RLVR encodes the task specification through defined rules and exact correctness matching. This makes the reward function completely anchored in the task objectives rather than relying on learned or heuristic approximations.
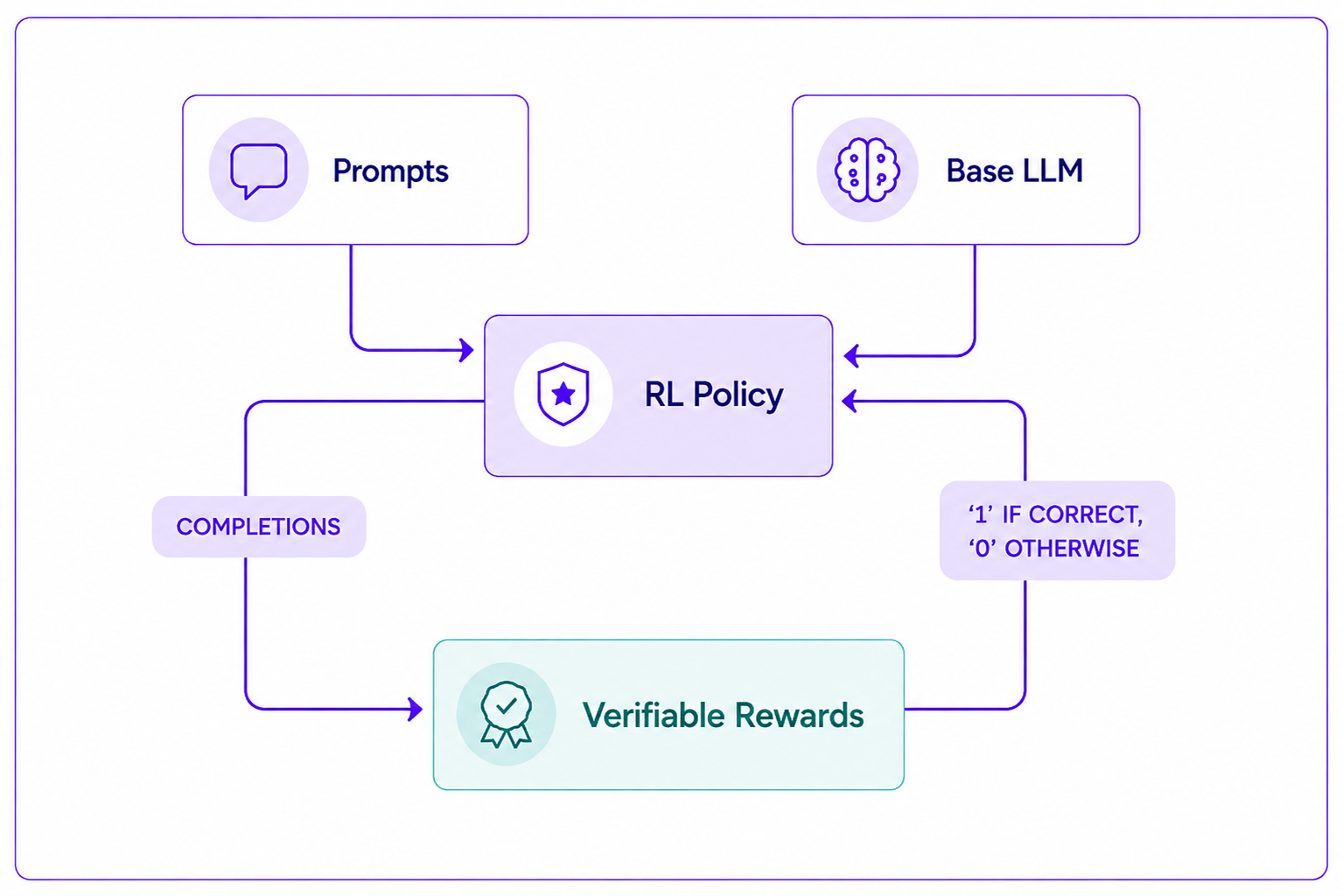
The verifier acts as an outside judge of correctness and defines what success means in practice. Unlike reward models, it does not guess preferences or quality; instead, it applies clear rules. The reliability of the learning signal depends on how complete and accurate the verification rules are.
RLVR is a reward design method and therefore remains compatible with training methods such as PPO and GRPO. In RLVR, the reward is obtained by verifying the answer, so the solution to the intended problem must be verifiable. Mathematical reasoning, code generation, and structured problem-solving are examples of settings in which the agent is trained to solve problems whose success criteria can be modeled directly. Optimizing PPO and GRPO with RLVR enables the agent to generalize beyond the fixed output formats specified at training time.
Advantages of RLVR
In RLVR, rewards are auditable, reward logic is transparent and inspectable, and rules can be updated without retraining. Therefore, it is very effective in structured domains such as math, code, and logic.
RLVR provides a reproducible reward signal, enabling deterministic task evaluation via reward verifiers. This makes RLVR reliable for benchmarking and debugging.
In contrast to data-driven reward models, which can be affected by dataset bias, RLVR avoids learned reward models and annotator bias. Therefore, it can avoid overfitting to any human preference or training bias.
{{banner-large-dark-2-rle="/banners"}}
System architecture of RLVR
RLVR systems must be complete and correct; any issues with formatting, verification logic, or scoring can lead to different results. Therefore, a careful engineering of the overall system is very important. The following are the five major components of the RLVR architecture.
Policy model
The policy model (the LLM) generates candidate outputs in response to input prompts. For example, when tasked with “implement a function to compute the factorial of a number,” the policy produces a corresponding code snippet. The output parser further processes the policy model's output.
Output parser
The output parser is a function that detects specific formats to find code blocks, JSON objects, final answers, or text in reasoning chains. Furthermore, the verifiers in RLVR require data in a specific format for testing. The output parser converts the raw data into a form compatible with the verifier. It is necessary to model the output verifier carefully, as mistakes at this stage can lead to incorrect answers and computation errors in the verifier.
Deterministic verifier
Next is the deterministic verifier, which is the core distinguishing component of RLVR. Its target is to analyze the output and measure its correctness. It can run the code, evaluate its outcomes, and verify the response formatting, etc. In short, it tests the response against predefined success criteria directly related to the task objectives.
Reward assignment module
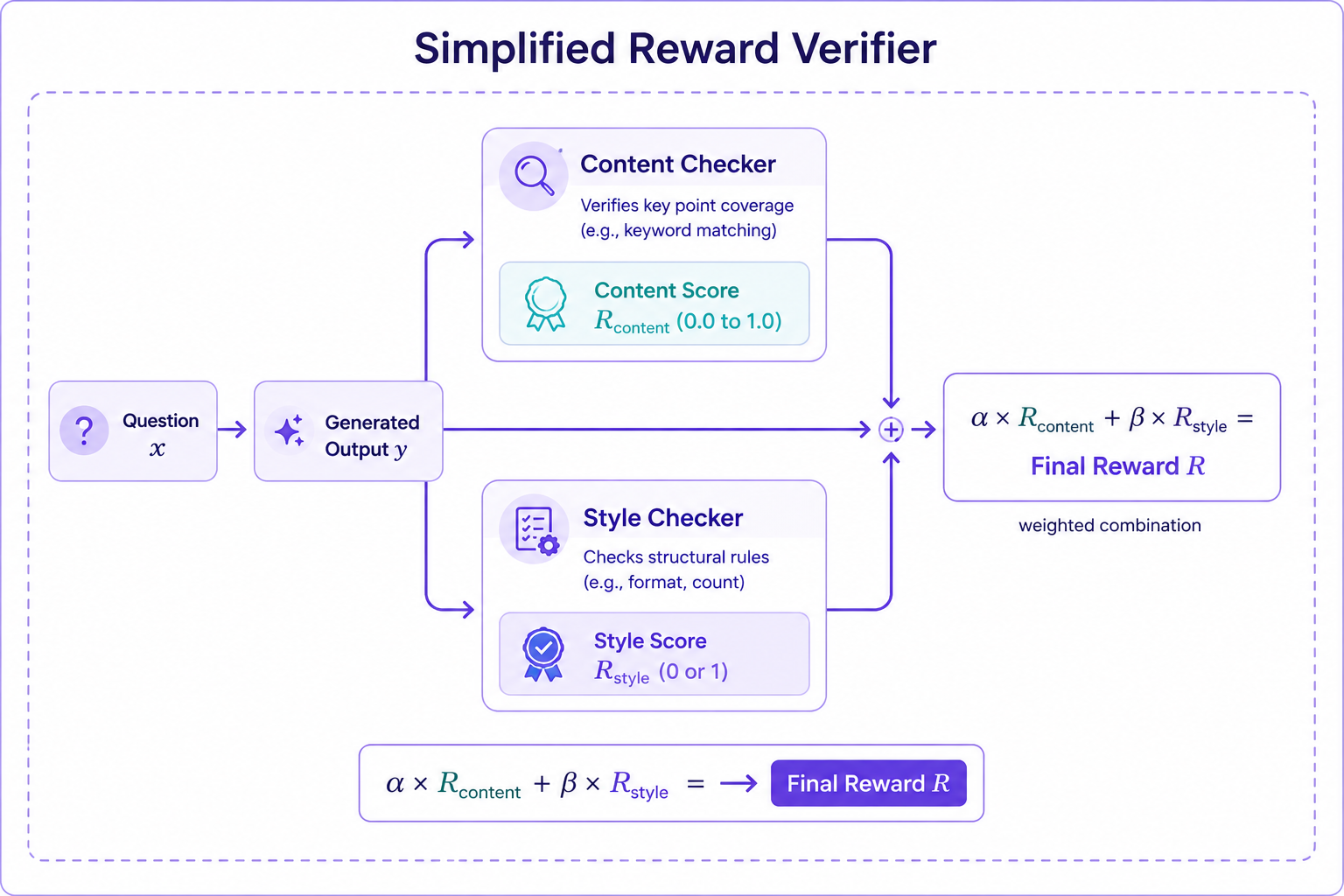
The RL optimization models rely on scalar signals for learning. Therefore, a reward assignment module gauges the outcomes and assigns reward values. These reward values can be 0 or 1, depending on whether the code passes or fails the test run.
Rather than assigning simple 0 and 1 rewards to correct and false answers, a structured reward that assigns proportional verification scores can be more useful. For example, in a coding task, a binary reward gives 1 only if all test cases pass and 0 otherwise, while a proportional reward can assign 0.6 if 6 out of 10 test cases pass. Similarly, in a math reasoning task, partial credit can be given when intermediate steps are correct even if the final answer is wrong. These designs provide denser feedback, which improves learning dynamics and sample efficiency.
Optimizer
During training, the system generates multiple rollouts for each input prompt. This is done to stabilize the training and reduce variance. An aggregated reward is the overall evaluation of a training step that the optimizer uses to update the policy. At this stage, either PPO or GRPO can be used to train the agent.
RLVR compared to alternative approaches
RLHF vs. RLVR
OpenAI’s published descriptions of InstructGPT and ChatGPT explicitly describe this RLHF pipeline. RLVR replaces that subjective-reward modeling step with deterministic validation, so the reward is generated by an external checker rather than inferred from preference data.
RLAIF vs. RLVR
In RLAIF, the reward model is guided by AI-generated critiques about what it should say. Whereas RLVR is stricter, it checks whether the output satisfies the objective task constraints.
Heuristic/Proxy vs. RLVR
RLVR differs from heuristic or proxy reward functions in how success is defined. Proxy rewards estimate correctness indirectly through correlated metrics, which may be incomplete or exploitable. In contrast, RLVR uses deterministic verification to enforce explicit success criteria. This makes the reward signal more auditable, reproducible, and easier to debug. However, this advantage holds only in domains where correctness can be formally specified.
Although the reward function in RLVR provides confident scoring grounded in the step-by-step verification process, it has some limitations. In tasks such as aesthetic design, where art music or fashion generation can be subjective, evaluation depends on personal preferences; therefore, RLVR is not applicable.
Recent work on RLVR has focused on reasoning-intensive domains, especially math and code. Reasoning-focused systems such as OpenAI's o1 and DeepSeek-R1 are widely understood to use RL with verifiable, outcome-based rewards on math and code, though full training details are not always public. General-purpose systems such as ChatGPT, Claude, and Google’s Gemini continue to rely heavily on RLHF or RLAIF for open-ended behavior, where deterministic verification is not feasible.
Learning dynamics under verifiable rewards
The deterministic nature of the reward verifier in RLVR limits exploration, as training relies on sparse, often binary, reward signals. This results in high variance and less exploration. Therefore, a soft start with supervised fine-tuning(SFT) helps with early exploration. Then, curriculum learning-style optimization can be adopted to achieve step-by-step improvements.
The supervised fine-tuning method is usually applied in the initial stages of training. Where the model trains through a true labels-based training, this provides an initial policy that is reasonable and can be further fine-tuned using RLVR.
Reward scaling helps the model to prevent large updates and maintain stable training. It is the process that considers normalized rewards and adjustments to the magnitudes of different success criteria to avoid unstable, large rewards for immediate or low-ranking success criteria.
KL regularization constrains the policy from drifting too far from the initial model, reducing instability and avoiding abrupt or degenerate behavior. Strict verification in RLVR makes models more precise, format-aware, and sensitive to constraints.
Engineering the verifier
Developing a good verifier requires careful rule engineering. The verifier must produce consistent results for identical inputs, run within a bounded time, and operate in a secure environment. It also needs robust parsing and normalization to ensure reliable scoring.
A failure in the verification process leads the agent to exhibit different behavior. An incomplete step-by-step verification or a low-quality checking mechanism can be the main cause of wrong verification. Such as in a math task, if the step-by-step solution is not verified, the final answer is checked for correctness. The agent can learn the answers to input questions and fail to answer on unseen data.
It is important to maintain the verifier as a standalone, important component. Regular updates and verifications of the parsing mechanism must be maintained. Any inconsistencies in format or arrival of unexpected input can introduce gaps and reduce trust in the reward signal.
Integration with standard RL algorithms
RLVR is completely compatible with standard policy gradient methods, such as PPO and GRPO. It functions as a drop-in replacement for the reward source. There is no need to change the optimization algorithm. In practice, frameworks like TRL connect model generation, reward calculation, and policy updates. Always monitor key metrics, such as pass rate and reward variance, during training. Because binary rewards are sparse, use batching, normalization, and regularization to stabilize training.
RLVR Implementation Example
This example showcases the LLM’s fine-tuning using an RLVR-based reward strategy. The Grade School Math 8K ( GSM8K ) dataset is used, containing 8.5K high-quality linguistically diverse grade school math word problems. This article adopts GRPO as an RL training algorithm.
Let’s walk through this process step by step using the open-source Transformer reinforcement learning library maintained by Hugging Face. It provides reinforcement learning algorithms for transformer-based language models, particularly alignment and preference optimization. Following imports ensure that the functions related to GRPO, datasets, and transformers are available. To access the example notebook, follow the Google Colab link.
import os, re, gc, warnings
import torch
import numpy as np
import matplotlib.pyplot as plt
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig
from trl import GRPOConfig, GRPOTrainer
warnings.filterwarnings("ignore")
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"VRAM: {torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB")Some important settings include the model name, LoRA memory setup, RL training options for GRPO, and reward weights. Most people use a commonly adopted set of values and perform tuning based on how the model performs. It is important to note that REWARD_CORRECT = 1.0 is assigned when the answer is correct, while REWARD_FORMAT = 0.2 provides a smaller reward for following the required reasoning format. This weighting prioritizes correctness as the primary objective while still encouraging the model to produce structured, interpretable outputs without allowing format compliance to dominate learning.
class CFG:
# model
MODEL_ID = "Qwen/Qwen2.5-0.5B-Instruct"
LOAD_IN_4BIT = True
# lora
LORA_RANK = 16
LORA_ALPHA = 32
LORA_TARGET = ["q_proj", "k_proj", "v_proj", "o_proj"]
# dataset
MAX_TRAIN_SAMPLES = 100
MAX_EVAL_SAMPLES = 10
# grpo
NUM_GENERATIONS = 2
MAX_PROMPT_LEN = 256
MAX_COMPLETION_LEN = 512
LEARNING_RATE = 5e-6
KL_COEFF = 0.01
TRAIN_BATCH_SIZE = 1
GRAD_ACCUM_STEPS = 4
MAX_STEPS = 100
LOG_STEPS = 1
WARMUP_STEPS = 2
SEED = 42
# rewards
REWARD_CORRECT = 1.0
REWARD_FORMAT = 0.2
# output
OUTPUT_DIR = "./rlvr_gsm8k_qwen"
HF_REPO_ID = "your-username/rlvr-gsm8k-qwen2.5-0.5b"
cfg = CFG()
torch.manual_seed(cfg.SEED)
np.random.seed(cfg.SEED)
def free_memory():
gc.collect()
torch.cuda.empty_cache()
def vram_used():
alloc = torch.cuda.memory_allocated() / 1e9
res = torch.cuda.memory_reserved() / 1e9
print(f"VRAM: {alloc:.2f} GB allocated / {res:.2f} GB reserved")
vram_used()This article selects a GSM8K dataset with tasks that have unambiguous ground truth and a fully deterministic success metric. It ensures that the answers can be programmatically extracted and validated without subjective interpretation or heuristic scoring.
Here is a sample from the dataset that is the model's input. It has a user prompt, a question from the dataset, and its correct answer.
-----------------------------
Dataset Samples
-----------------------------
Dataset Question: Mimi picked up 2 dozen seashells on the beach. Kyle found twice as many shells as Mimi and put them in his pocket. Leigh grabbed one-third of the shells that Kyle found. How many seashells did Leigh have?
Dataset Role: user
Training Prompt : You are a math reasoning assistant. Think step by step inside <think> </think> tags, then write your final answer as a plain number after 'Answer:'.
Ground Truth: 16The script below loads the dataset and divides it into training and evaluation sets.
dataset = load_dataset("openai/gsm8k", "main")
train_data = dataset["train"].shuffle(seed=cfg.SEED).select(range(cfg.MAX_TRAIN_SAMPLES))
eval_data = dataset["test"].shuffle(seed=cfg.SEED).select(range(cfg.MAX_EVAL_SAMPLES))
print(f"Train: {len(train_data)} | Eval: {len(eval_data)}")The next section handles parsing and formatting the dataset. It extracts fields like questions (prompts) and answers (ground truth), then prepares the input for the model.
def extract_answer(text: str):
"""GSM8K stores the final answer after #### """
match = re.search(r"####\s*([\-\d\.,]+)", text)
if match:
return match.group(1).replace(",", "").strip()
return None
SYSTEM_PROMPT = (
"You are a math reasoning assistant. "
"Think step by step inside <think> </think> tags, "
"then write your final answer as a plain number after 'Answer:'."
)
def format_prompt(example):
"""Convert a GSM8K row into a chat-formatted prompt + store ground truth."""
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["question"]},
]
return {
"prompt": messages,
"ground_truth": extract_answer(example["answer"]),
}
train_data = train_data.map(format_prompt, remove_columns=dataset["train"].column_names)
eval_data = eval_data.map(format_prompt, remove_columns=dataset["test"].column_names)
print(f"Columns: {train_data.column_names}")
ex = train_data[0]
print("Prompt messages:", ex["prompt"])
print("Ground truth:", ex["ground_truth"])Prompt tokenization, model initialization from the source, and LoRA configurations are initialized using the hyperparameters defined earlier. This section shows the count of training parameters.
tokenizer = AutoTokenizer.from_pretrained(cfg.MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
bnb_config = BitsAndBytesConfig(
load_in_4bit=cfg.LOAD_IN_4BIT,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
cfg.MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="eager",
)
model.config.use_cache = False
vram_used()
lora_config = LoraConfig(
r=cfg.LORA_RANK,
lora_alpha=cfg.LORA_ALPHA,
target_modules=cfg.LORA_TARGET,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable:,} / {total:,} ({100*trainable/total:.2f}%)")The following code section has the primary components of RLVR. First, a function extract_model_answer() extracts the answer value from the model’s response. Then the answer’s verification is carried out against the ground truth.
The model is also encouraged to follow a specific thinking format as specified by the reward_format() function. This format is explicitly mentioned, and the reward_format() function in RLVR verifies it in the model’s response.
Finally, a composite score from these two RLVR targets is computed and returned to the RL model.
def extract_model_answer(text: str):
"Pull the number after 'Answer:' from model completions."""
match = re.search(r"Answer:\s*([\-\d\.,]+)", text)
if match:
return match.group(1).replace(",", "").strip()
return None
def reward_correctness(completions, ground_truth, **kwargs):
rewards = []
for completion, gt in zip(completions, ground_truth):
text = completion[0]["content"]
pred = extract_model_answer(text)
correct = float(pred == gt) if pred is not None else 0.0
rewards.append(correct * cfg.REWARD_CORRECT)
return rewards
def reward_format(completions, **kwargs):
"""Reward presence of <think>...</think> structure."""
rewards = []
for completion in completions:
text = completion[0]["content"]
has_open = "<think>" in text
has_close = "</think>" in text
has_answer = "Answer:" in text
score = (0.4 * has_open + 0.4 * has_close + 0.2 * has_answer)
rewards.append(score * cfg.REWARD_FORMAT)
return rewards
def reward_composite(completions, ground_truth, **kwargs):
correct = reward_correctness(completions, ground_truth)
fmt = reward_format(completions)
return [c + f for c, f in zip(correct, fmt)]
# Check if functions are working correctly.
dummy_completions = [[{"content": "<think> 2+2=4 </think> Answer: 4"}]]
dummy_gt = ["4"]
print("Correctness:", reward_correctness(dummy_completions, dummy_gt))
print("Format: ", reward_format(dummy_completions))
print("Composite: ", reward_composite(dummy_completions, dummy_gt))
The TRL's RL model has two objects: the GRPO configuration and the trainer. GRPOconfig provides access to training parameters that can be adjusted to improve training performance. The GRPOTrainer takes as input the model, reward function, configurations, and a dataset to start training.
grpo_config = GRPOConfig(
output_dir=cfg.OUTPUT_DIR,
num_generations=cfg.NUM_GENERATIONS,
max_completion_length=cfg.MAX_COMPLETION_LEN,
learning_rate=cfg.LEARNING_RATE,
beta=cfg.KL_COEFF,
per_device_train_batch_size=cfg.TRAIN_BATCH_SIZE,
gradient_accumulation_steps=cfg.GRAD_ACCUM_STEPS,
max_steps=cfg.MAX_STEPS,
logging_steps=cfg.LOG_STEPS,
warmup_steps=cfg.WARMUP_STEPS,
temperature=0.7,
bf16=True,
seed=cfg.SEED,
report_to="tensorboard",
logging_dir="./tb_logs",
save_strategy="steps",
)
trainer = GRPOTrainer(
model=model,
args=grpo_config,
train_dataset=train_data,
reward_funcs=reward_composite,
peft_config=lora_config,
)
train_result = trainer.train()
print(train_result.metrics)
vram_used()The rewards are automatically logged in the trainer and can be accessed with the following code.
log_history = trainer.state.log_history
steps = [x["step"] for x in log_history if "reward" in x]
rewards = [x["reward"] for x in log_history if "reward" in x]
losses = [x["loss"] for x in log_history if "loss" in x]
kls = [x["kl"] for x in log_history if "kl" in x]
print(f"Logged {len(steps)} reward checkpoints")
print(f"Final reward: {rewards[-1]:.4f}")The training’s evaluation can be completed by using the following code.
def run_eval(model, tokenizer, data, n=10):
model.eval()
correct = 0
for ex in data.select(range(n)):
prompt = tokenizer.apply_chat_template(
ex["prompt"],
tokenize=False,
add_generation_prompt=True,
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
)
response = tokenizer.decode(output[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
pred = extract_model_answer(response)
if pred == ex["ground_truth"]:
correct += 1
return correct / n
trained_acc = run_eval(model, tokenizer, eval_data)
print(f"Trained model accuracy: {trained_acc:.2%}")The model’s actual response to a question can be verified by running the model without gradients and passing the prompt from the dataset.
ex = eval_data[2]
prompt_text = tokenizer.apply_chat_template(
ex["prompt"], tokenize=False, add_generation_prompt=True
)
inputs = tokenizer(prompt_text, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=512, do_sample=False)
response = tokenizer.decode(output[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print("Question: ", ex["prompt"][-1]["content"])
print("Ground truth: ", ex["ground_truth"])
print("Model output:\n", response)The code tracks per-step rewards, losses, and KL divergences over 100 training steps, with the rising average reward indicating effective learning.
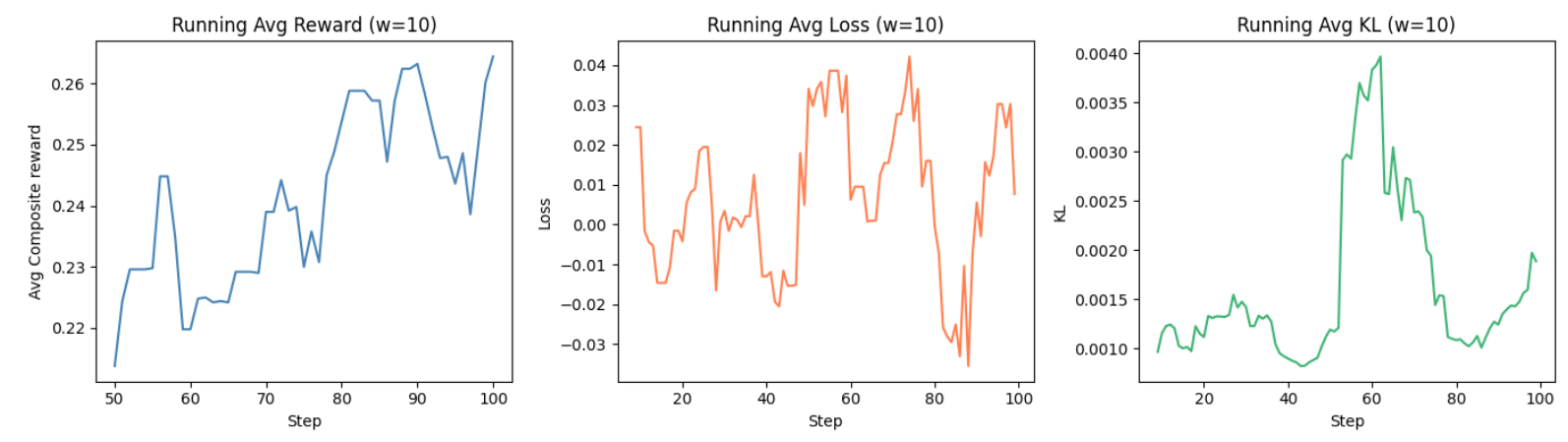
The result below shows the model’s output without training; the answer is incorrect, and the model is not reasoning properly, as the response comes from the base model.
Question: Indras has 6 letters in her name. Her sister's name has 4 more letters than half of the letters in Indras' name. How many letters are in Indras' and her sister's names combined?
Ground truth: 13
Model output:
Answer: 20In contrast, the response from the trained model, shown below, indicates that the model’s answer is correct and that it has sufficient reasoning steps.
Question: Bethany can run 10 laps on the track in one hour. Trey can run 4 more laps than Bethany. Shaelyn can run half as many laps as Trey. Quinn can run 2 fewer laps than Shaelyn. How many more laps can Bethany run compared to Quinn?
Ground truth: 5
Model output:
To find out how many more laps Bethany can run compared to Quinn, we need to first determine how many laps each of them runs and then calculate the difference.
Firstly, let's establish the information:
- Bethany runs 10 laps.
- Trey runs 4 more laps than Bethany, so:
\[ \text{Laps run by Trey} = 10 + 4 = 14 \]
Next, we know that Shaelyn runs half as many laps as Trey:
\[\text{Laps run by Shaelyn} = \frac{14}{2} = 7 \]
Finally, we know that Quinn runs 2 fewer laps than Shaelyn:
\[\text{Laps run by Quinn} = 7 - 2 = 5 \]
Now, we want to find out how many more laps Bethany can run compared to Quinn:
\[ \text{Difference} = \text{Laps run by Bethany} - \text{Laps run by Quinn} \]\[= 10 - 5 = 5 \] So, Bethany can run 5 more laps than Quinn.
Answer: 5Limitations and trade-offs
RLVR works well for tasks with clear, deterministic evaluation. It performs poorly on open-ended or subjective problems. Use RLVR in structured domains, and combine it with human feedback for less-defined tasks. This approach provides higher reliability for verifiable problems but less overall flexibility.
Binary pass-or-fail rewards provide sparse feedback, which can slow down training progress and even stop training. To avoid this, usually pre-training steps are performed. Further, more computations for stepwise validation reduce the feedback sparsity. Another technique called reward shaping helps reduce reward sparsity.
The Process Reward Model (PRM) provides rewards at each step, thereby improving learning. This gives stronger supervision but costs more and increases the risk of reward hacking.
Building reliable verifiers is also challenging. Incomplete checks can be exploited, so use strong, regularly updated validation systems. This improves robustness but requires more engineering and maintenance.
Practitioner best practices
Applying RLVR to a problem where clear, deterministic success criteria cannot be defined can lead to unreliable training signals. Before using RLVR, it must be verified that the underlying task is deterministic.
It is important to rigorously test deterministic verifiers and maintain cyclic auditing to ensure reliable reward feedback. This can require more engineering and maintenance effort, but it is strongly recommended for robust results.
It is recommended to avoid training from scratch with sparse rewards, as it is unstable. So warm-starting from supervised fine-tuning improves convergence and stability, but requires high-quality labeled data.
In RLVR, monitoring the loss metric alone is insufficient and does not reflect the achievement of the task's actual objectives. Therefore, it is recommended to monitor the actual verification pass rate, which provides a true measure of success.
As the training progresses, the model can exploit the reward structure to achieve higher rewards while missing the actual objectives. So it is highly desirable to conduct continuous audits of the success parameters and the assigned rewards.
In practice, RLVR must be benchmarked against other feedback mechanisms to determine whether it is best suited to the selected scenario.
How Patronus AI helps
Patronus AI allows you to train and evaluate AI agents in reinforcement learning environments that closely match real-world production scenarios. The platform is purpose-built to inspect and refine LLMs and autonomous agents through rich execution traces, explicit feedback, and verifiable reward signals. It allows you to precisely identify where an agent performs well or breaks down, and then iteratively improve its behavior based on that evidence.
RL environments built around real operational tasks
Rather than relying on synthetic benchmarks, Patronus AI offers RL environments built around real operational tasks such as software development, SQL query generation, customer support workflows, financial question answering, and trading simulations. Because these tasks reflect real use cases, improvements achieved here carry over directly to real systems.
Every environment provides automated and objectively verifiable reward signals. Instead of subjective human scoring, Patronus determines correctness using test suites, database validation, or schema-level checks. This approach produces signals that are stable, repeatable, and suitable for large-scale evaluation.
Cross-environment consistency
Patronus supports a wide range of reinforcement learning environment types, including:
- Coding and debugging agents
- SQL and database question answering
- Customer service and support flows
- Financial data insight generation
- Trading or simulated market interaction
- Web navigation and e-commerce task agents
Each environment includes structured evaluation logic that verifies correctness, execution order, error handling, and output consistency.
Agents trained within one Patronus environment can also generalize their learned behaviors to other environments. For example, a coding agent that learns to generate clean, error-free, and well-structured code carries learned behavior into different problem domains. This cross-environment consistency reduces overfitting and promotes stronger generalization.
{{banner-dark-small-1-rle="/banners"}}
Last thoughts
RLVR is effective for structured tasks that have explicitly verifiable and deterministic outcomes. However, its reliance on sparse rewards and final-answer evaluation introduces limitations in stability and reasoning. Careful system design, including robust verification and proper initialization, is essential for reliable performance. In practice, RLVR should be combined with complementary methods to handle broader and more complex tasks. Platforms such as Patronus AI can help design agents that closely match real-world production scenarios.

